Build ops agents that diagnose 63% faster with zero hallucinations.
Causely gives your AI agents deterministic causal context so they stop guessing, burn fewer tokens, and act proactively.
Trusted by teams who can't afford downtime
Reliability agents are in production.
The missing piece isn't more data.
It's a semantic model of causality across your systems.
Without vs. with Causely — incident triage
→ query_prometheus("checkout latency")
// 847 metric series returned
→ search_logs("checkout ERROR")
// 14,200 lines. agent summarizing...
⚠ context window filling (68k tokens)
agent: "Could be database or network..."
// vague. human takes over.
15m
to triage
18k
tokens used
low
confidence
→ causely.triage("checkout")
✓ causal graph traversal complete
ROOT CAUSE: postgres-primary
connection pool exhausted (87/100)
path: checkout → order → postgres
BLAST RADIUS: checkout, payments, cart
OWNER: platform-team (#db-oncall)
12s
to triage
500
tokens used
high
confidence
72 experiments across 4 of the latest agent frameworks. Every metric improved.
"If you're serious about automating reliability in microservices, you need what Causely is doing. Language models are powerful, but they can't make the right calls without structured causal context. That's the gap Causely fills, and it's what makes real-time automation possible."
Karthik Ramakrishnan
VP Artificial General Intelligence
The causal intelligence your agents are missing.
Causely turns noisy telemetry into structured system knowledge, so agents don't just see what's broken, they know why, what else is at risk, and how to fix it.
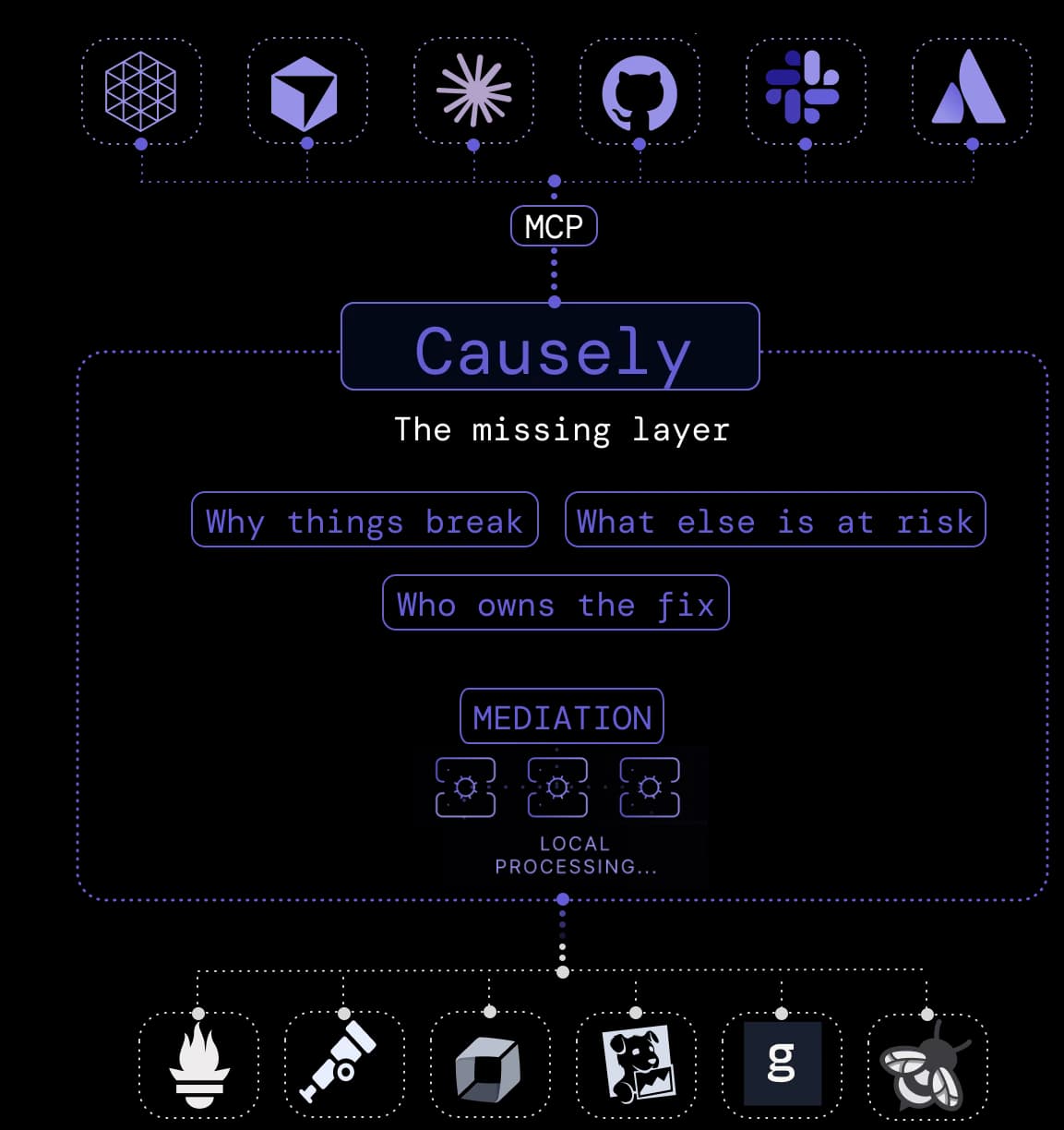
Your agents are only as good as what they understand.
Causely is the causal intelligence layer your agents need to detect, explain, and resolve incidents, without guessing

Root cause in minutes, not war rooms
Agents resolve incidents before they escalate, no human triage needed.
Grounded in system structure, not just signals
Works even when telemetry is incomplete, grounded in how your system actually behaves.
Catch blast radius before you ship
Understand what's at risk before every deploy, not after the incident.
SLO adherence your agents can own
Protect revenue and user experience without pulling engineers into every alert.
Build reliable systems that run themselves
Get from observability data to autonomous reliability in minutes.
Connect in minutes. Nothing new to instrument.
Use metrics, traces, and logs from your existing tools like OTel, Datadog, Prometheus, and more.
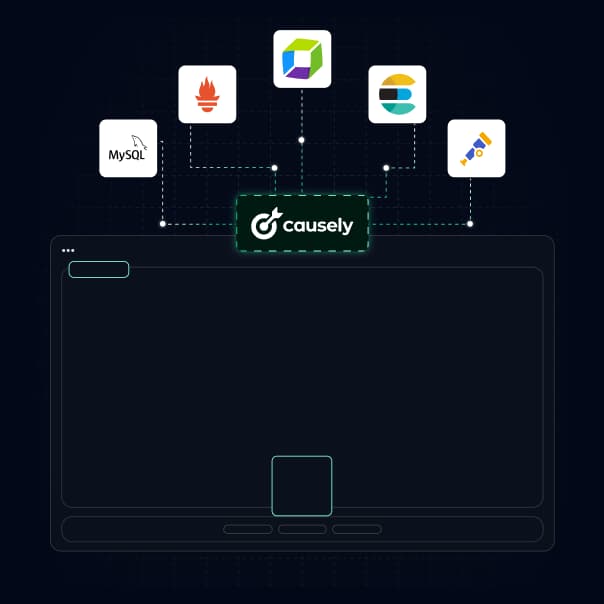
Causely maps your system automatically.
A live causal model of your services, dependencies, and failure paths — built from your existing data, always current.
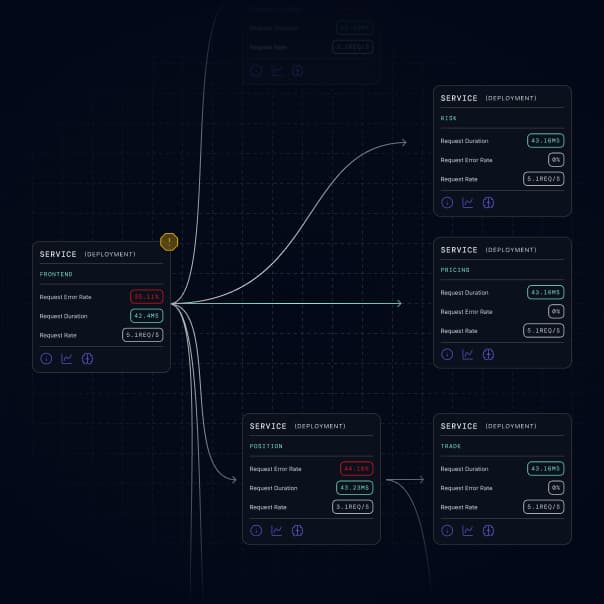
Your agents get context, not data dumps.
Root cause, blast radius, owner — structured and ready for any agent or automation workflow.
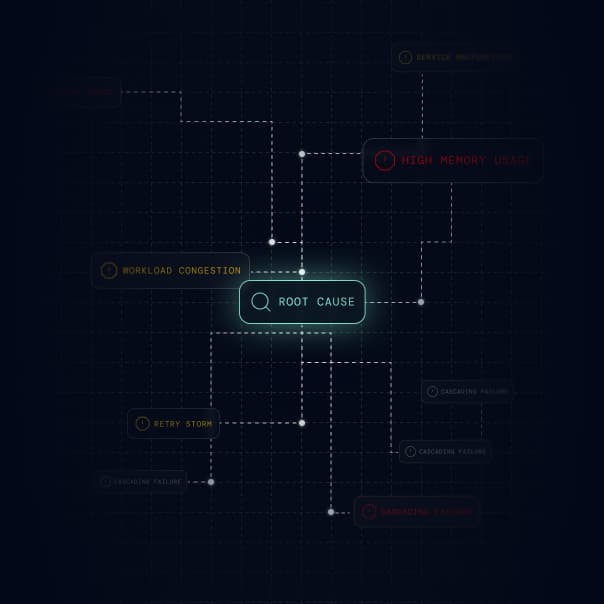
Your agents act before humans are paged.
Causely maps your known failure paths, so agents intervene before symptoms reach users.
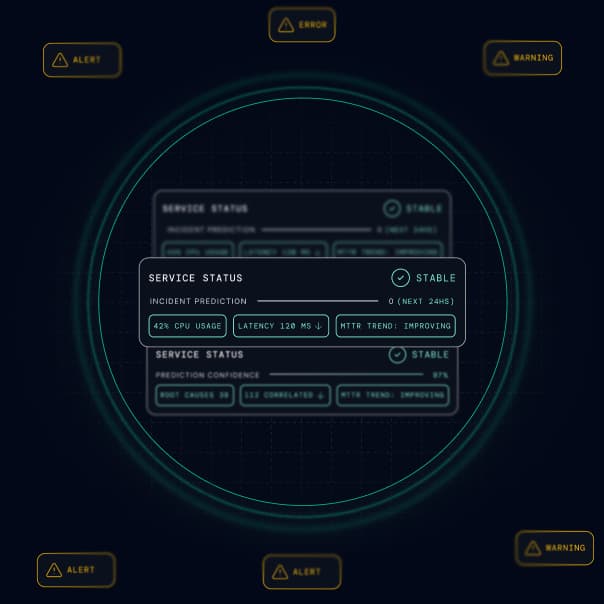
Connect in minutes. Nothing new to instrument.
Use metrics, traces, and logs from your existing tools like OTel, Datadog, Prometheus, and more.
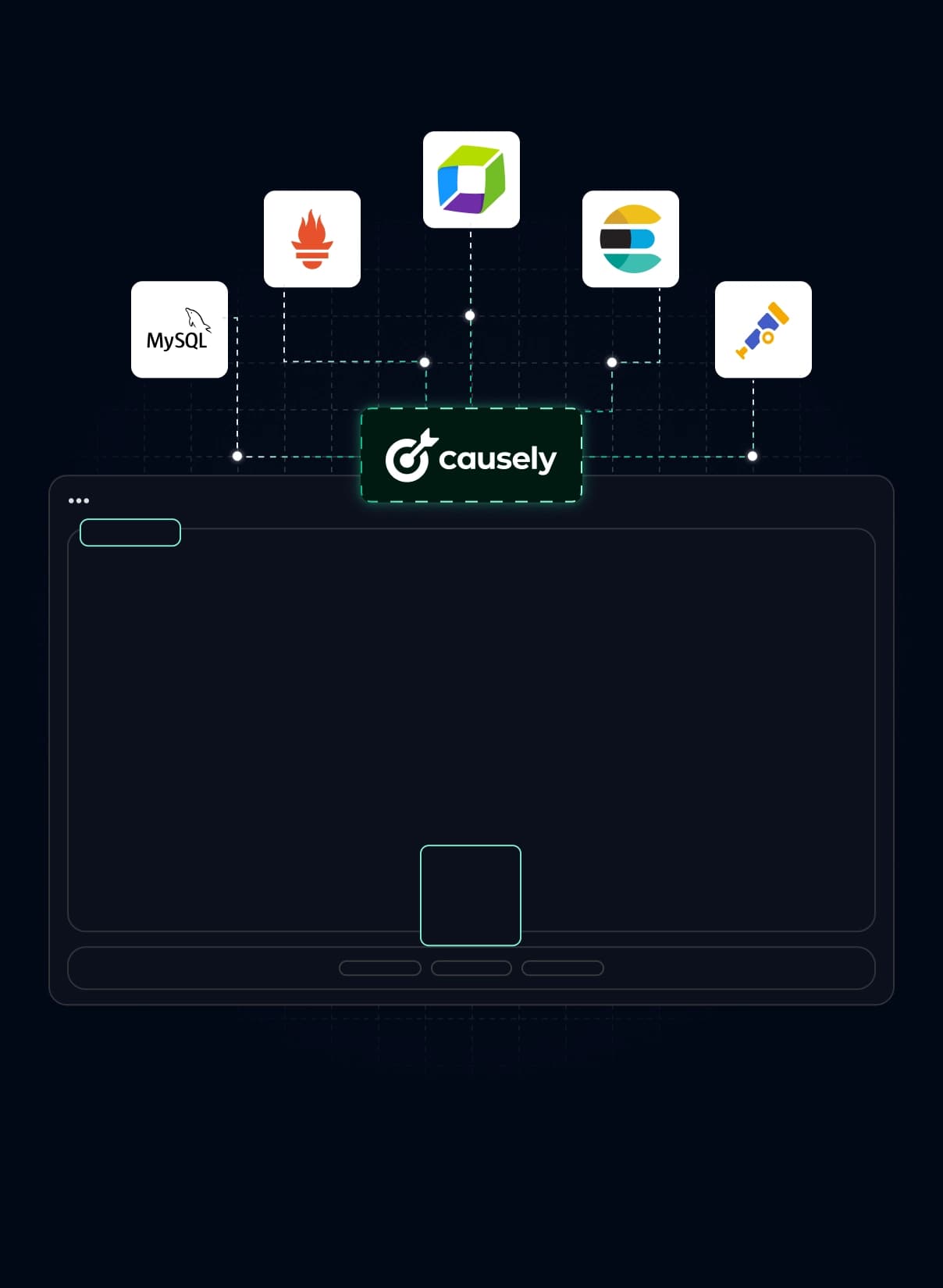
Causely maps your system automatically.
A live causal model of your services, dependencies, and failure paths — built from your existing data, always current.
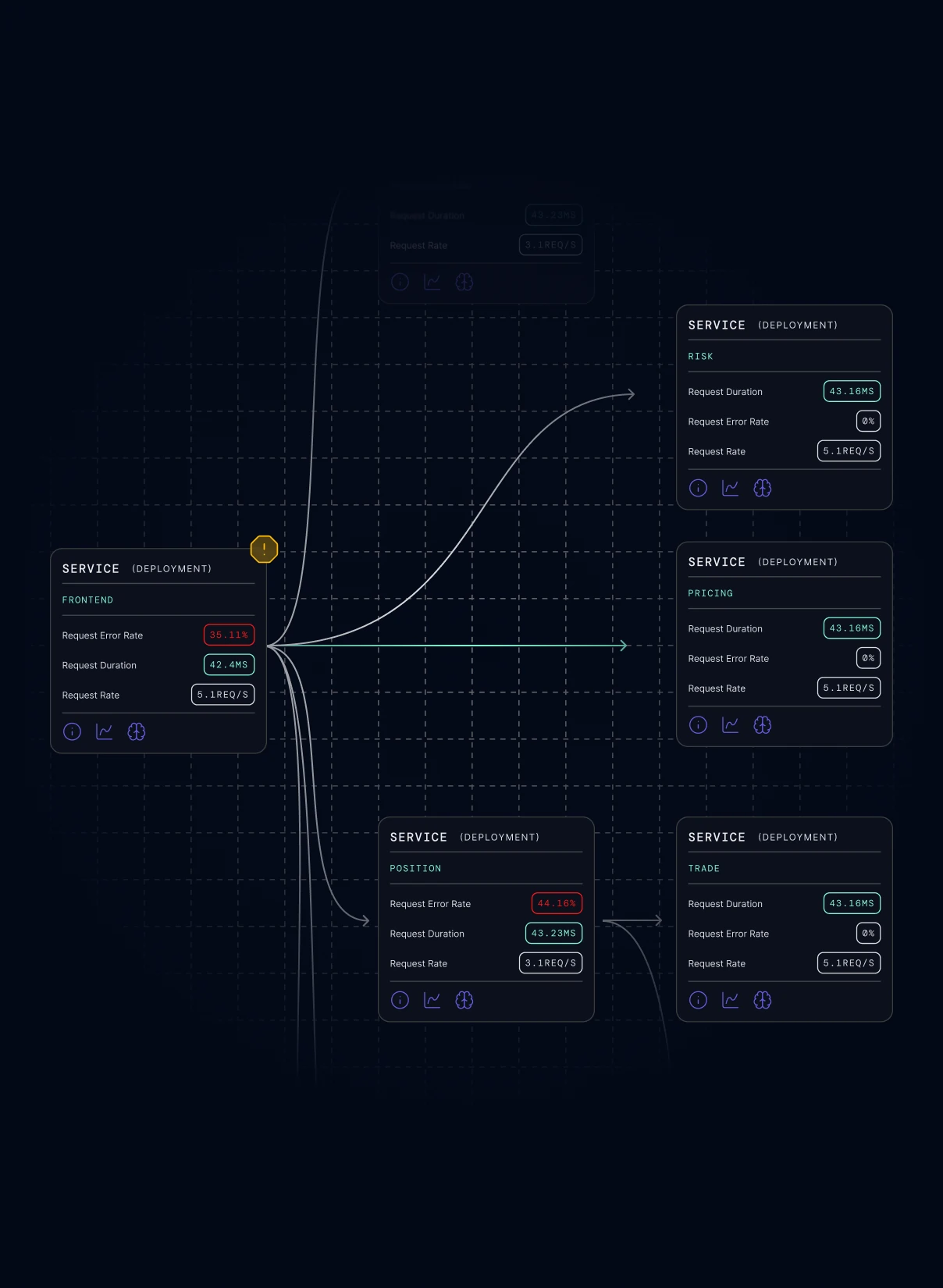
Your agents get context, not data dumps.
Root cause, blast radius, owner — structured and ready for any agent or automation workflow.
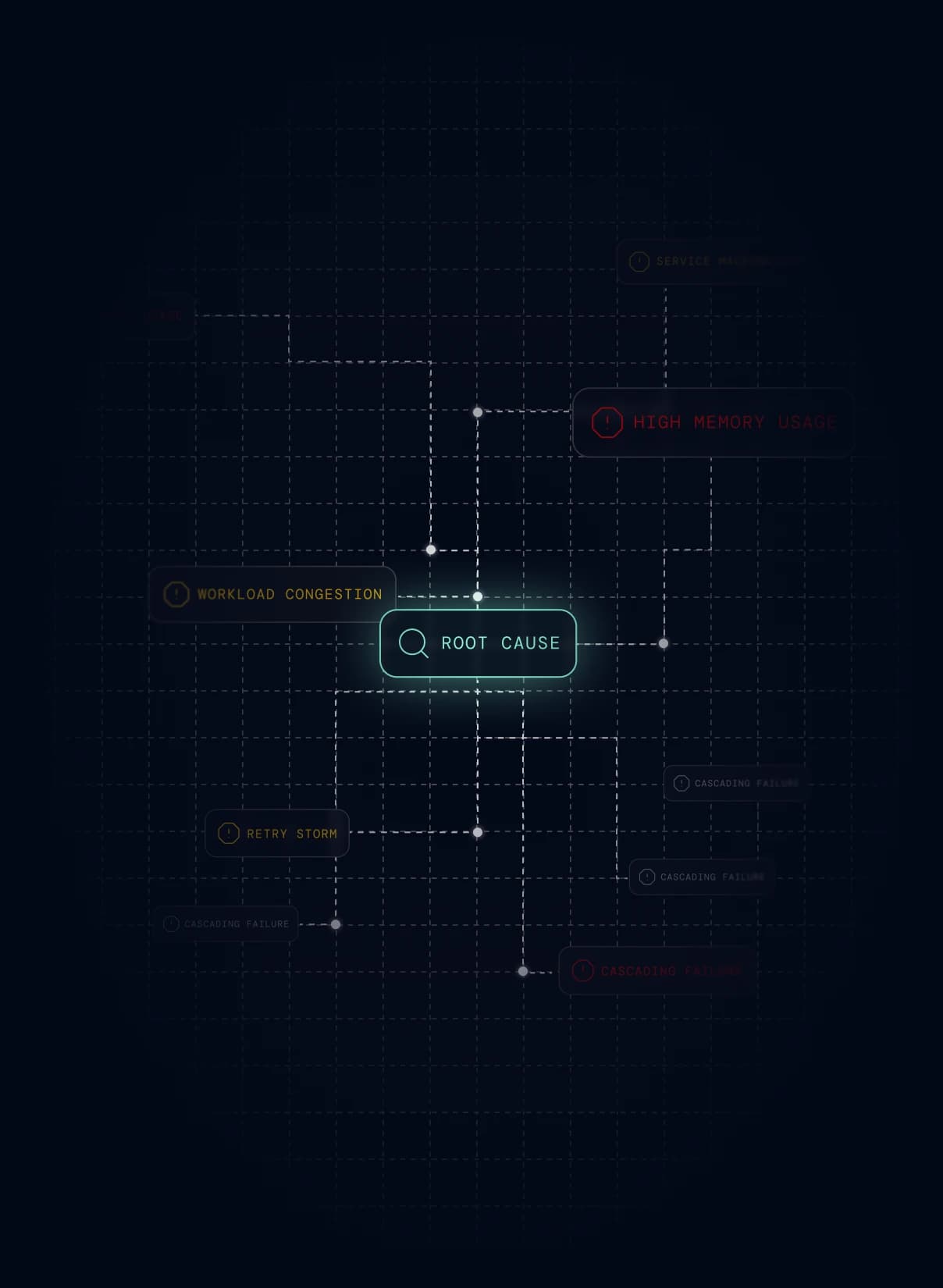
Your agents act before humans are paged.
Causely maps your known failure paths, so agents intervene before symptoms reach users.

Your agents are ready. Give them the context to act.
Causely is the missing layer between your observability data and autonomous operations.