In 2025, I resolve to be proactive about reliability
Enlin Xu
January 15, 2025

What developers can do in 2025 to be proactive and prevent incidents before they happen, without sacrificing development time
So far this week, we’ve talked about the difficulties involved with troubleshooting and the complexity of dealing with escalations. What if we could head off these problems before they even happen?
Making changes to production environments is one of the riskiest parts of managing complex systems. Even a small, seemingly harmless tweak—a configuration update, a database schema adjustment, or a scaling decision—can have unintended consequences. These changes ripple across interconnected services, and without the right tools, it’s nearly impossible to predict their impact.
Business needs speed and agility in introducing new capabilities and features but without scarifying reliability, performance and predictability. Hence, engineers need to know how a new feature, or even a minor change, will affect performance, reliability, and SLO compliance before it goes live. But existing observability tools lack the required capabilities to provide useful insights that enable engineers to safely deploy new features. The result? Reduced productivity, slowdown in feature development, and reactive firefighting when changes go wrong -- all leading to downtime, stress, and diminished user trust.
Recently, we worked with a customer who sought to shift their reactive posture to one that more aggressively seeks out problems before they happen. With this customer, a bug within one of their microservices (the data producer) caused the producer to stop updating the Kafka topic with new events. This created a backlog of events for all the consumers of this topic. As a result, their customers were looking at stale data. Problems like this lead to poor customer experience and revenue loss, so many customers need to adopt a preventative mode of operations.
This post explores how this trend can be disrupted by providing the analytics and the reasoning capabilities to transform how changes are made, empowering teams to anticipate risks, validate decisions, and protect system stability—all before the first line of code is deployed.
Being proactive is easier said than done
Change management is a process designed to ensure changes are effective, resolve existing issues, and maintain system stability without introducing new problems. At its core, this process requires a deep understanding of both the system’s dependencies and its state before and after a change.
Production changes are risky because engineers typically lack sufficient visibility into how changes will impact the behavior of entire systems. What seems like an innocuous change to an environment file or an API endpoint could have far-reaching ramifications that aren’t always obvious to the developer.
While observability tools have come a long way in helping teams monitor systems, they lack the analytics required to understand, analyze, and predict the reliability and performance behavior of cloud-native systems. As a result, engineers are left to “deploy and hope for the best” ... and get a 3AM call when things didn’t work as expected. And, while we live in a veritable renaissance of developer tooling, most of these tools focus on developer productivity, not developer understanding, of whole systems and the consequences of changes made to one component or service.
It’s hard to predict the impact of code changes
When planning a change, the priority besides adding new functionality is to confirm whether it addresses the specific service degradations or issues it was designed to resolve. Equally important is ensuring that the change does not introduce new regressions or service degradations.
Achieving these goals requires a comprehensive understanding of the system’s architecture, particularly the north-south (layering) dependencies and the east-west (service-to-service) interactions. Beyond mapping the topology, it is crucial to understand the data flow within the system—how data is processed, transmitted, and consumed—because these flows often reveal hidden interdependencies and potential impact areas.
Even minor configuration changes can create cascading failures in distributed systems. For instance, adjusting the scaling parameters of an application might inadvertently overload a backend database, causing performance degradation across services. Engineers often rely on experience, intuition, or manual testing, but these methods can’t account for the full complexity of modern environments.
Unpredictable performance behavior of microservices
As we discussed in our post yesterday, loosely coupled microservices communicate with each other and share resources. But which services depend on which? And what resources are shared by which services? These dependencies are continuously changing and, in many cases, unpredictable.
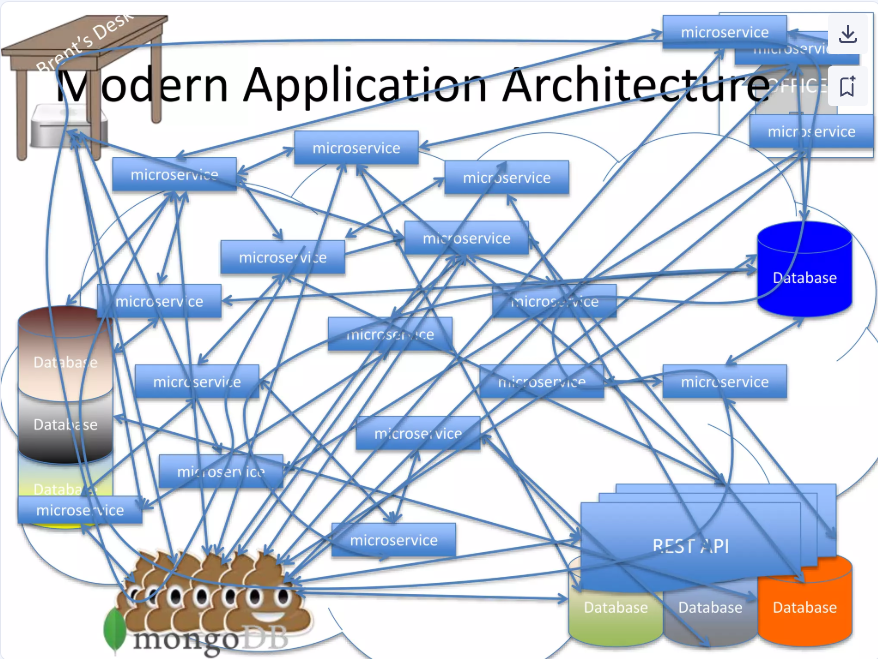
A congested database may cause performance degradations of some services that are accessing the database. But which one will be degraded? Hard to know. Depends. Which services are accessing which tables through what APIs? Are all tables or APIs impacted by the bottleneck? Which other services depend on the services that are degraded? Are all of them going to be degraded?
These are very difficult questions to answer. As a result, analyzing, predicting, and even just understanding the performance behavior of each service is very difficult. Furthermore, using existing brittle observability tools to diagnose how a bottleneck cascades across services is practically impossible.
There’s a lack of “what-if” analysis tools for testing resilience
Even though it’s important to simulate and test the impact of changes before deployment, the tools currently available are sorely lacking. Chaos engineering tools like Gremlin and Chaos Monkey simulate failures, but don’t evaluate the impact of configuration changes. Tools like Honeycomb provide event-driven observability, but don’t help much with simulating what will happen with new builds. Inherently, if the tools can’t analyze the performance behavior of the services, they can’t support any “what-if” analysis.
Developer tools are inherently focused on the “build and deploy” phases of the software lifecycle, meaning they prioritize pre-deployment validation over predictive insights. They don’t provide answers to critical questions like: “How will this change impact my service’s reliability or my system’s SLOs?” or “Will this deployment create new bottlenecks?”
Predictive insights require correlating historical data, real-time metrics, dependency graphs, and most importantly deep understanding of the microservices performance behaviors. Developer tools simply aren’t built to ingest or analyze this kind of data at the system level.
Developer and operations tools today are both insufficient
Developer tools are essential for building functional, secure, and deployable code, but they are fundamentally designed for a different domain than observability. Developer tools focus on ensuring “what” is built and deployed correctly, while observability tools aim to identify “when” something is happening in production. The two domains overlap but rarely address the full picture.
Bridging this gap often involves integrating developer workflows—such as CI/CD pipelines—with observability systems. While this integration can surface useful metrics and automate parts of the release process, it still leaves a critical blind spot: understanding “why” something is happening. Neither traditional developer tools nor current observability platforms are designed to address the complexity of dynamic, real-world systems.
To answer the “why,” you need a purpose-built system to unravel the interactions, dependencies, and behaviors that drive modern production environments.
Building for reliability
Building reliable performing applications was never easy, but it has become much harder. As David Shergilashvili correctly states in his recent post Microservices Bottlenecks, “In modern distributed systems, microservices architecture introduces complex performance dynamics that require deep understanding. Due to their distributed nature, service independence, and complex interaction patterns, microservices systems' performance characteristics differ fundamentally from monolithic applications.”
Continuing to collect data and presenting it to developers in pretty dashboards with very little or no built-in analytics to provide meaningful insights won’t get us to build reliable distributed microservices applications.
To accurately assess the impact of a change, the state of the system must be assessed both before and after the change is implemented. This involves monitoring key indicators such as system health, performance trends, anomaly patterns, threshold violations, and service-level degradations. These metrics provide a baseline for evaluating whether the change resolves known issues and whether it introduces new ones. However, the ultimate goal goes beyond metrics; it is to confirm that the known root causes of issues are addressed and that no new root causes emerge post-change.
We need to build systems that enable engineers to introduce new features quickly, efficiently, and most importantly safely, i.e., without risking the reliability and performance of their applications. Reasoning platforms with built-in analytics need to provide actionable insights that anticipate implications and prevent issues. These systems must have the following capabilities:
- Services dependencies. Be able to capture, represent and auto-discover service dependencies. Without this knowledge a developer can’t know and anticipate which services may be impacted by a change.
- Causality knowledge. Be aware of all potential failures and the symptoms they may cause. Without these insights, a developer can’t assess the risk of introducing a change. Is the application code I am about to change a single point of failure? What will happen if for some reason my new code won’t perform as expected?
- Performance analysis. Understanding the blast radius of performance bottlenecks. Without having a deep understanding of the interactions between the microservices as well as their shared resources, developers can’t predict all possible situations that may occur in production. Even the best tester can’t cover all possible scenarios. How can you know how a noisy neighbor will impact your application in production?
- What-if. The ability to assess load fluctuations before they happen or potential impacts of code changes to be introduced. Is your service ready for the predicted Black Friday traffic? What about the dependent upstream service?
Causely can help you build better cloud-native applications
Our Causal Reasoning Platform is a model-driven, purpose-built AI system delivering multiple analytics built on a common data model. You can learn more about what makes it unique here.
With Causely, you can go from reactive troubleshooting to proactive design, development, and deployment of reliable cloud-native applications.
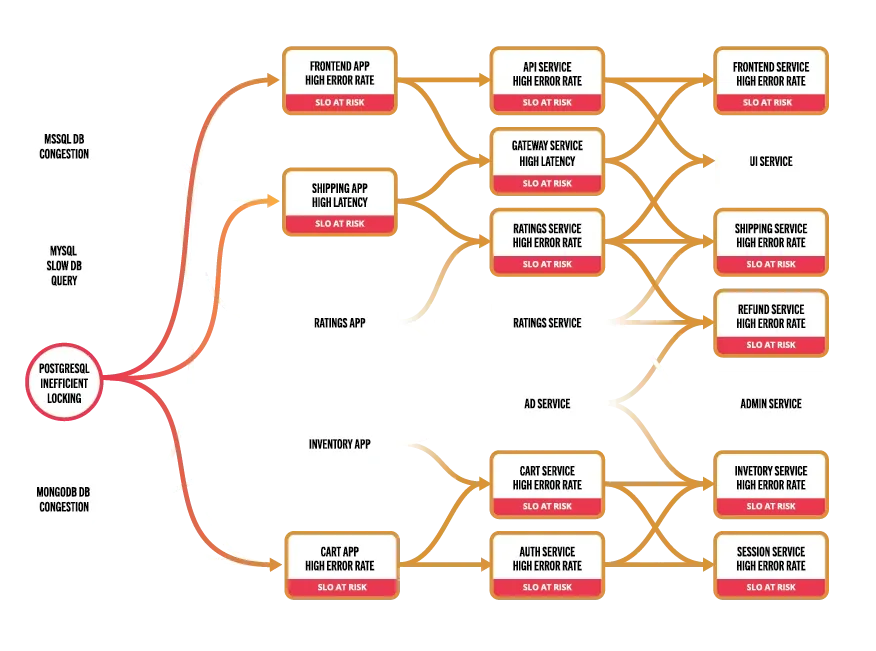
Conclusion
Making changes to production environments shouldn’t be a guessing game. Without the right systems, even the smallest change can introduce risks that compromise reliability, breach SLOs, and erode user trust. Reactive approaches to troubleshooting only address problems after they occur, leaving engineers stuck firefighting rather than innovating.
A purpose-built reasoning platform can flip this narrative. By incorporating predictive analytics, “what-if” modeling, and automated risk detection, teams can anticipate issues before they arise and deploy with confidence. Platforms like Causely empower engineers with the insights they need to write reliable code, validate changes, and ensure system stability at every step.
Book a meeting with the Causely team and let us show you how you can bridge the gap between development and observability to build better, more reliable cloud-native applications.
