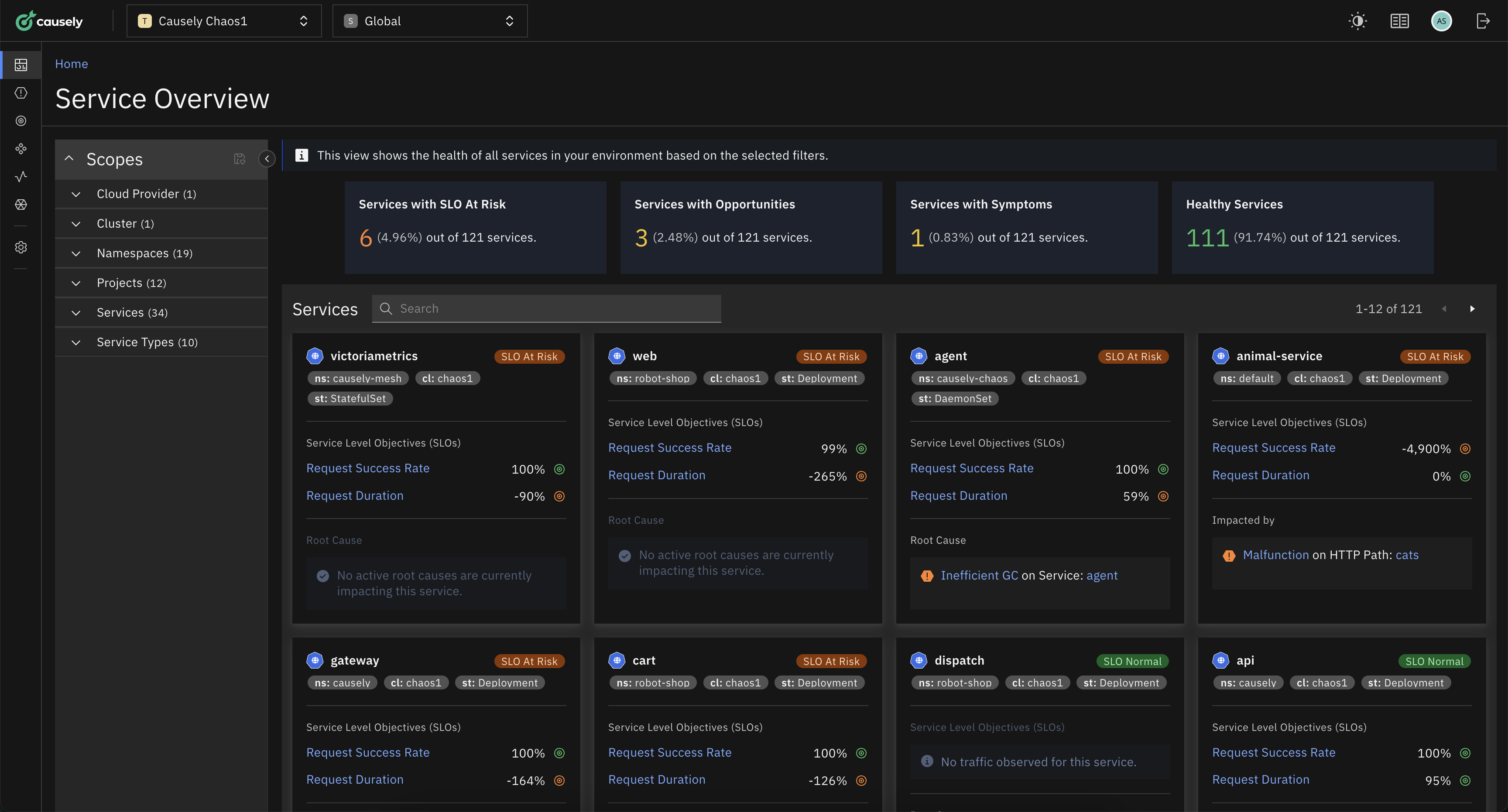
Causal Reasoning: The Missing Piece to Service Reliability
Endre Sara
April 22, 2025

Assuring service reliability is the most critical goal of IT. It was never easy, and it is getting increasingly complex as businesses require greater speed, agility, and scalability to stay competitive and respond quickly to changing market demands. These needs are driving the adoption of microservices architectures, enabling organizations to build and deploy applications with increased flexibility, resilience, and efficiency at scale.
But there are no free lunches -this adoption comes with a cost. As organizations adopt microservices, they encounter new operational challenges. Microservices architectures are dynamic, ever evolving and loosely coupled with intricate dependencies and interactions between services. Although built with standardized building blocks and common patterns, the emergent behavior of each system is unique and constantly changing as components are rewritten, upgraded, or replaced. The simplicity of small, loosely coupled services can quickly become overshadowed by the complexity of managing hundreds (or thousands) of interdependent components.
Continuing the decades long trend in Observability of collecting more and more data won’t get us to the desired state of assuring service reliability. Furthermore, feeding this data to a machine and hoping the machine will magically generate the answers required to continuously assure service reliability is a false hope. Machines trained on yesterday's data may be able to understand the past but cannot make the real-time decisions necessary to continuously assure service levels, especially in cloud-native environments given the dynamic nature of such environments.
At Causely, we believe that the key to overcoming these challenges lies in causal knowledge captured as part of an ontology, to enable reasoning about cause-and-effect relationships in complex systems. This stands in contrast to the industry's growing reliance on simply sending alerts to Large Language Models (LLMs), and we believe causal reasoning is the critical missing piece for autonomous service reliability.
Why Traditional Approaches Fall Short
Some organizations attempt to address reliability by dumping vast amounts of raw, unstructured telemetry into ML algorithms in the hope of surfacing meaningful patterns. When anomalies are detected, these observations are sometimes passed to LLMs to generate plausible explanations. While this can help contextualize events, it often falls short where it matters most. LLMs, by design, are general-purpose tools trained on broad, historical data. They excel at pattern recognition and language generation but lack the deep, real-time causal reasoning needed to adapt to novel, dynamic environments. They may describe "what" happened, but they struggle to uncover "why" it happened and "what" to do about it in a new, unseen context. Even when LLMs are fine-tuned on telemetry patterns, they generalize across environments. But reliability failures are context specific. What broke in one deployment doesn’t explain a novel failure in another deployment.
Example 1 – Misleading Latency Correlations Across Services:
In a microservices-based e-commerce platform, a simultaneous latency spike was observed in the checkout, inventory, and payment services. Observability tools showed strong correlations between these services, leading engineers to suspect the inventory service as the root cause. However, the real issue was a slow database query in the product-catalog service, which affected the three components above. The correlation misled the team into focusing on the wrong area, demonstrating the limitations of correlation without causal context.
Example 2 – Misinterpreting Memory Spikes as Service Defects:
An alert for repeated pod restarts in the recommendation engine, accompanied by memory spikes across backend services, led engineers to suspect a memory leak. Observability tools flagged backend services as anomalous based on correlated metrics. However, the actual root cause was a recent frontend change that dramatically increased the frequency and size of incoming requests. The backend services were merely reacting to an upstream trigger. This highlights how correlation can obscure the true origin of a problem, especially when external factors are involved.
Relying on statistical correlation alone can be dangerous. Correlations can be misleading without causal grounding, leading teams to chase false positives, miss root causes, or implement ineffective remediations.
Beyond Monitoring: Towards Autonomous Operations
Traditional observability focuses on "what" happened. Causal Reasoning focuses on “why”. Causal Reasoning captures, represents, understands and analyzes cause-and-effect relationships and uses these, among other inferences, to automatically infer root cause based on observed anomalies. By embracing Causal Reasoning, organizations can move beyond the reactive model of monitoring and alerting to a world of autonomous operations, where systems can diagnose and heal themselves with minimal human intervention. This is essential for achieving the promise of resilient, scalable, always-on cloud-native applications.
Causal Reasoning is driven by ontology. An ontology is a formal model that defines:
- The types of entities, attributes and relationships in a domain, including root causes and symptoms
- The relationships that can exist between entities, including the causality relationships between root causes and symptoms, and attribute dependencies
- The behaviors or constraints (e.g., "a pod can be scheduled on one node ", "a pod can have multiple containers")
It’s like the grammar and vocabulary for talking about a subject.
Causal Reasoning uses a knowledge graph to organize the real-world information based on the ontology
- Nodes are specific instances of entities (e.g., checkout-service, inventory-service, payment-service, production-database)
- Edges are actual relationships between the instances (e.g., checkout-service -> depends_on -> production-database)
- Edges can also be relationship between attribute dependencies (e.g. “calls to a user facing API invokes the backend GRPC method”, “backend GRPC method invocation produces async messages on a specific topic”)
- Metadata: e.g. CPU usage, error logs, deployment time, configs
The knowledge graph is the filled-out version of the ontology, populated with facts. The discovered topology of a microservices application is a knowledge graph, which describes the application components and their relationships using an ontology. It describes what is like a semantic network, but it doesn’t say anything about why or what will happen if something changes.
Using the ontology and the knowledge graph Causal Reasoning automatically generates a causal graph. A causal graph is a directed acyclic graph (DAG) with focus on why things happen:
- Nodes are specific causes and observations
- Directed edges that represent causal links, not just association
- Example: DatabaseMalfunction -> causes -> ClientServiceErrors
- Allows you to ask "what if" questions:
- What happens to service errors if the database is recovered?
In short, a knowledge graph describes what is connected to what, while a causal graph, describes what causes what.
Causal Reasoning: Engineering Intelligence into Service Operations
The causal knowledge in the ontology captures essential system behaviors and relationships without getting lost in the weeds. Driven by the causal knowledge, causal reasoning enables engineering teams focus on what matters. Instead of reacting to every blip on a dashboard, casual reasoning drives a top-down focus on the critical causes that impact service reliability.
Using causal reasoning, we can:
- Understand why a service's performance degraded, not just that it did.
- Infer the root causes instead of guessing based on symptoms.
- Develop proactive, preventive strategies instead of reactive firefighting.
Causal reasoning empowers teams to diagnose, remediate, and even predict and prevent risks to service-level objectives (SLOs) with clarity and confidence.
Causely: A Purpose-built Autonomous Reliability System
At Causely, we’ve developed a purpose-built Causal Reasoning Platform for service reliability. The key tenets of the platform are:
- Causal model: an ontology describing cloud-native application environments, including the causal knowledge of root causes, symptoms and causality between them
- Topology graph: a knowledge graph of the specific managed environment. The graph is generated automatically by discovering the managed environment.
- Abductive inference engine: an engine that automatically generates a causality graph from the ontology and the topology graph and used it in real time to infer root causes based on observed symptoms/anomalies
Causely solves a problem that no other vendor is solving by delivering
- Clarity in Complexity: Our models scale with your systems, maintaining meaningful insights even as your architecture evolves and grows more intricate.
- Actionable Insights: We don't just flag anomalies—we infer root causes and deliver clear, prioritized paths to resolution.
- Proactive Prevention: With an ontology and causal reasoning, we spot risks before they become incidents, shifting organizations from reactive to proactive.
- Seamless Integration: Our platform integrates with your workflows and CI/CD pipelines, delivering instant value without requiring manual retraining or rule-writing.
Conclusion
We do see LLMs as a powerful technology that can benefit from and combined together Causal reasoning, stay tuned for more on that.
Causal Reasoning is the foundation of Causely’s solution. It empowers organizations to cut through complexity, deliver precise insights, prevent downtime, and free engineers to focus on what matters most: innovation.
Let us show you the power of causal reasoning and cross-organizational collaboration in cloud-native environments. See Causely for yourself. Book a meeting with the Causely team or start your free trial now.
#cloudnative #servicereliability #causalreasoning #abstraction #siteReliabilityEngineering #sre #DevOps #observability #AI #ML