In 2025, I resolve to spend less time troubleshooting
Christine Miller
January 13, 2025

What SREs and developers can do in 2025 to make troubleshooting more manageable
Troubleshooting is an unavoidable part of life for SREs and developers alike, and it often feels like an endless grind. The moment a failure occurs, the clock starts ticking. If the failure impacts a mission critical application, every second counts. Outages can cost hours of wasted productivity, to say nothing of lost revenue and pricing concessions when you’ve violated an SLO. Pinpointing the root cause requires sifting through piles of logs, metrics that blur together, and false positives. Troubleshooting becomes a search for a needle in a haystack, and to make things even more complex, the needle may not even be in the haystack. Furthermore, when the failure originates in your scope of control, the pressure intensifies—you’re expected to resolve it quickly, minimize downtime, and restore service without disrupting the rest of your work. It’s a reactive process, and it’s draining.
But it doesn’t have to be this way. By adopting systems that solve the root cause analysis problem and automate troubleshooting, you can shift troubleshooting from a time-consuming, heavy-lifting chore to a streamlined task. Automated root cause analysis cuts through the noise and pinpoints the issue in no time.
With the right approach, troubleshooting becomes a quick, manageable part of your day, freeing you to focus on building systems that don’t just react better but fail less often.
What do we mean by troubleshooting?
In a distributed microservices environment, troubleshooting often begins with an alert from the monitoring system or user feedback about degraded performance, such as increased latency or error rates. Typically, these issues are first observed in the service exposed to end users, such as an API gateway or frontend service. However, the root cause often lies deeper within the service architecture, making initial diagnosis challenging. The development team must begin by confirming the scope of the issue, correlating the alert with specific user-reported problems to identify whether it is isolated or systemic.
The next step involves tracing the source of the alert within the service ecosystem. Using distributed tracing tools like OpenTelemetry, the team tracks requests as they propagate through various microservices, identifying where bottlenecks or failures occur. Concurrently, a service dependency map, often visualized through monitoring platforms, provides a bird’s-eye view of interactions between services, databases, caches, and other dependencies, helping to pinpoint potential hotspots in the architecture.
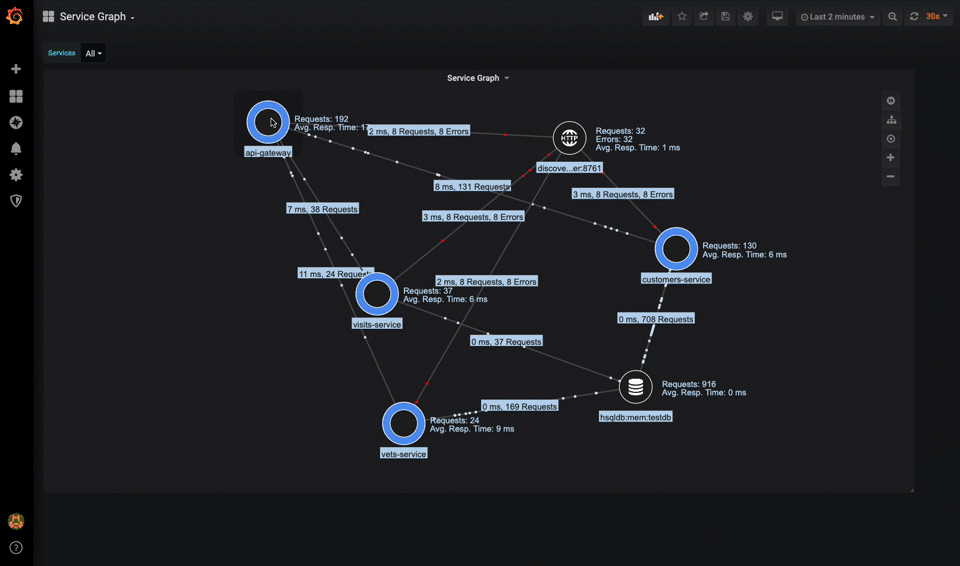
Example service dependency map. Source: Grafana
Once the potential hotspots are identified, developers turn to metrics and logs for further insights. Resource utilization metrics, such as CPU, memory, and disk I/O, are analyzed to detect bottlenecks, while logs reveal specific errors or anomalies like timeouts or failed database queries. This analysis attempts to correlate symptoms with the timeline of the issue, offering clues to its origin. Often, the team experiments with quick fixes, such as scaling up CPU, memory, or storage for the affected services or infrastructure. While these adjustments might temporarily relieve symptoms, they rarely address the root cause and must be rolled back if ineffective.
When resource adjustments fail, a deeper dive into the affected components is necessary. Distributed traces provide detailed insights into slow transactions or failures, highlighting which services or calls are problematic. Developers then use continuous profiling tools to examine runtime data for each service, identifying resource-intensive methods, excessive memory allocations, or inefficient call paths. This granular analysis helps uncover inefficiencies or regressions in code performance.
If the issue involves a database, further investigation focuses on query performance. Database profiling tools are used to analyze query execution times, frequency, and data volume. Developers assess whether queries are taking longer than usual, retrieving excessive data, or being executed too frequently. This step often reveals issues such as missing indexes, inefficient joins, or unoptimized queries, which could be contributing to overall service degradation. By iteratively analyzing and addressing these factors, the root cause of the problem is eventually resolved, restoring system stability and performance.
Troubleshooting is reactive, time-consuming, and exhausting. Developers should be focusing their time and energy (and their company’s investment) on innovation, yet troubleshooting forces them to turn their attention elsewhere.
Troubleshooting doesn’t have to dominate your role; with the right systems, it can become efficient and manageable.
Troubleshooting is hard
When trying to find the root cause of service or application outages or degradations, developers face numerous challenges:
- It’s hard to pinpoint which service is the source of the degradations amid a flood of alerts
- It’s hard to diagnose and remediate the root cause
- It’s hard to see the forest from the trees
It’s hard to pinpoint which service is the source of the degradations amid a flood of alerts
Failures propagate and amplify through the environment. A congested database or a congested resource will cause application starvation and service degradation that cascades throughout the system. Even if you deploy an observability tool to monitor the database or the resource, you may observe nothing on the database or the resource. And if you deploy an observability tool to monitor the applications and services, you will be flooded with alerts about application starvation and service degradations. Given the flood of alerts, pinpointing the bottleneck is very complex. As described above, it entails a time-consuming, heavy lifting, manual process under pressure.
The more observability tools you deploy, the more data you collect and the harder the problem gets. More alerts, more noise, more data you need to sift through. This is a journey to nowhere, a trajectory you want to reverse.
Diagnosing and remediating the root cause of a problem is hard
Pinpointing the congested service, database or resource is hard and inefficient. Even if you know where the root cause is, you may not know what the root cause is. Without knowing what the root cause is, you can’t know what to remediate nor how to remediate.
Whether pinpointing where the bottleneck is or pinpointing what the root cause is, engineers rely on manual workflows to sift through logs, metrics, and traces. While new observability tools have emerged over the past decade focusing on cloud-native application infrastructure, and the traditional old guards have expanded their coverage to monitor the new technology landscape, neither has solved the problem. Some may do a better job than others in correlating anomalies or slicing and dicing the information for you, but they leave it to you to diagnose and pinpoint the root cause, leaving the hardest part unsolved. Furthermore, most of them require time consuming setup and configuration, deep expertise to operate, and deep domain knowledge to realize their benefits.
In practice, this means engineers are still performing most of the diagnostic work manually. The tools may be powerful, even elegant, but they don’t address the core challenge: diagnosing and remediating root causes remains a slow, resource-intensive process, particularly when time is of the essence during an incident. These gaps prolong resolution times, increase stress, and reduce time for proactive system improvements.
It’s hard to see the forest from the trees
Once the engineers turn to dashboards to investigate further, they stare at dashboards created by bottom-up tools. These tools collect a lot of data (often at great cost) and present this data in their dashboards without regard to the purpose of the information and the problem that needs to be solved. Engineers sift through metrics, logs, and time-series data, trying to understand context, composition, and dependencies so they can manually piece together patterns and correlations. This is highly labor-intensive and drives the engineer to get lost in the weeds without understanding the big picture of how the business or the service is impacted. Are service level objectives (SLOs) being violated? Are SLOs at risk?
Take your favorite observability tool. It probably excels at visualizing time-series data. However, it requires engineers to manually connect trends across dashboards and services, which can be especially challenging in distributed systems. Similarly, application performance management (APM) tools provide rich metrics and infrastructure insights, but the sheer volume of data presented in their dashboards can overwhelm users, making it difficult to focus on the most relevant information.
These tools, while powerful, often fall short in helping engineers see the forest from the trees. Instead of guiding engineers toward the right priorities and actionable insights about the broader system or the root cause, or even better, automatically pinpointing the root cause and remediating, they frequently amplify the noise. Irrelevant data, ambiguous relationships, and false positives force engineers to wade through excessive details, wasting time and delaying resolution. The lack of a top-down perspective makes it harder to understand how symptoms connect to underlying problems, leaving engineers stuck in the weeds.
The negative consequences of troubleshooting today
The way troubleshooting is done today has serious ramifications for organizations, teams, and individuals. It affects business outcomes and quality of life.
Failing to meet the SLAs
Whether the goal is 5-nines, 4-nines, or even only 3-nines, if we continue to manually troubleshoot, we will never meet these SLAs. The table below illustrates how many minutes in a month the given SLA allows for downtime.
| Availability % | Downtime per year | Downtime per quarter | Downtime per month | Downtime per week | Downtime per day (24 hours) |
|---|---|---|---|---|---|
| 90% ("one nine") | 36.53 days | 9.13 days | 73.05 hours | 16.80 hours | 2.40 hours |
| 99% ("two nines") | 3.65 days | 21.9 hours | 7.31 hours | 1.68 hours | 14.40 minutes |
| 99.9% ("three nines") | 8.77 hours | 2.19 hours | 43.83 minutes | 10.08 minutes | 1.44 minutes |
| 99.99% ("four nines") | 52.60 minutes | 13.15 minutes | 4.38 minutes | 1.01 minutes | 8.64 seconds |
| 99.999% ("five nines") | 5.26 minutes | 1.31 minutes | 26.30 seconds | 6.05 seconds | 864.00 milliseconds |
Source: High Availability, Wikipedia
3-nines means 99.9% uptime—in other words, all services are performing reliably at least 99.9% of the time. So, if any of the services is degraded for more than 43.2 minutes in a month, the 3-nines SLA is not met. Because of the length of time manual troubleshooting entails, a single incident in the month will cause us to miss delivering on a 3-nines SLA. And 3-nines is not even so great!
High Mean Time to Detect and Resolve (MTTD/MTTR)
The longer it takes to detect and resolve an issue, the greater the impact on customers and the business. Traditional troubleshooting workflows, which often rely on reactive and manual processes, are inherently slow. Engineers are forced to navigate through an overwhelming volume of alerts, sift through logs, and correlate metrics without clear guidance. This delay can lead to:
- Prolonged outages that damage user trust and satisfaction.
- Breaches of service level objectives (SLOs), which can result in financial penalties for organizations with stringent service level agreements (SLAs)
- Snowballing effects, where unresolved issues trigger secondary failures, compounding the problem and making resolution even more challenging.
Individual stress and burnout from constant reactive tasks
The reactive nature of troubleshooting takes a significant toll on individual engineers. When every incident feels like a race against the clock, the pressure to resolve issues quickly can become overwhelming. Engineers often work under constant stress, juggling:
- Interruptions to their regular work, leading to disrupted schedules and decreased productivity.
- Escalations where they are expected to step in as subject matter experts, often during nights or weekends.
- Repeated exposure to alert noise, which can cause decision fatigue and desensitization to critical alerts.
This relentless pace contributes to burnout. All it takes is a few hours of perusing the /r/sre subreddit to see that burnout is a very common issue among SREs and developers tasked with maintaining system reliability. Burnout not only affects individuals but also leads to higher attrition rates, disrupting team continuity and increasing hiring and training costs.
Reduced time for proactive reliability engineering
Troubleshooting dominates the time and energy of engineering teams, leaving little room for proactive reliability initiatives. As we will see later this week, proactive reliability engineering has extraordinary promise for the entire company: product/engineering, operations, business leaders. But instead of focusing on preventing incidents, engineers are stuck in a reactive loop. This trade-off results in:
- Delayed implementation of improvements that could enhance system stability and scalability.
- Accumulation of technical debt.
- A vicious cycle where the lack of proactive work increases the likelihood of future incidents, perpetuating the troubleshooting burden.
By constantly reacting to problems rather than proactively addressing underlying issues, teams lose the ability to innovate and build resilient systems. This dynamic not only affects engineering morale but also has broader implications for an organization’s ability to compete and adapt in fast-paced markets.
How troubleshooting should look
If we all recognize that the state of the art of troubleshooting is awful today, let’s work together to imagine a future where troubleshooting is routine and fast:
- Systems automatically pinpoint root causes within your domain quickly and accurately. Modern troubleshooting workflows must prioritize speed and precision. Systems should go beyond flagging symptoms and directly pinpoint the underlying cause within your domain.
- Actionable information provides necessary context upfront. Systems need to focus on identifying the actions and ideally automating the automatable.
- Troubleshooting workflows are streamlined. Workflows should be intuitive and efficient, designed to minimize context switching and maximize focus with unified dashboards that integrate with your operational workflows.
These systems must have certain capabilities to be effective:
- Causality. The ability to capture, represent, understand and analyze cause and effect relations.
- Reasoning. Generic analytics that can reason about causality and automatically pinpoint root causes based on observed symptoms.
- Automatic topology discovery. The ability to automatically discover the environment, the entities and the relationships between them.
With these systems, proper troubleshooting can drive positive business outcomes, such as:
- Delivering on SLOs and meeting SLAs. Reduce the number of incidents.
- Faster issue resolution, minimizing downtime. Reduce mean time to detect (MTTD) and mean time to resolve or recover (MTTR), keeping systems operational and minimizing the impact on users.
- Improved productivity by reducing time spent on reactive tasks. Enable engineers to focus on high-value innovation.
Causely automates troubleshooting
Our Causal Reasoning Platform is a model-driven, purpose-built AI system delivering multiple analytics built on a common data model. It is designed to make troubleshooting much simpler and more effective by providing:
- Out-of-the-box Causal Models. Causely is delivered with built-in causality knowledge capturing the common root causes that can occur in cloud-native environments. This causality knowledge enables Causely to automatically pinpoint root causes out-of-the-box as soon as it is deployed in an environment. There are at least a few important details to share about this causality knowledge:
- It captures potential root causes in a broad range of entities including applications, databases, caches, messaging, load balancers, DNS compute, storage, and more.
- It describes how the root causes will propagate across the entire environment and what symptoms may be observed when each of the root causes occurs.
- It is completely independent from any specific environment and is applicable to any cloud-native application environment.
- Automatic topology discovery. Cloud-native environments are a tangled web of applications and services layered over complex and dynamic infrastructure. Causely automatically discovers all the entities in the environment including the applications, services, databases, caches, messaging, load balancers, compute, storage, etc., as well as how they all relate to each other. For each discovered entity, Causely automatically discovers its:
- Connectivity - the entities it is connected to and the entities it is communicating with horizontally
- Layering - the entities it is vertically layered over or underlying
- Composition - what the entity itself is composed of
Causely automatically stitches all of these relationships together to generate a Topology Graph, which is a clear dependency map of the entire environment. This Topology Graph updates continuously in real time, accurately representing the current state of the environment at all times.
- Root cause analysis. Using the out-of-the-box Causal Models and the Topology Graph as described above, Causely automatically generates a causal mapping between all the possible root causes and the symptoms each of them may cause, along with the probability that each symptom would be observed when the root cause occurs. Causely uses this causal mapping to automatically pinpoint root causes based on observed symptoms in real time. No configuration is required for Causely to immediately pinpoint a broad set of root causes (100+), ranging from applications malfunctioning to services congestion to infrastructure bottlenecks.
In any given environment, there can be tens of thousands of different root causes that may cause hundreds of thousands of symptoms. Causely prevents SLO violations by detangling this mess, pinpointing the root cause that’s putting your SLOs at risk, and driving remediation actions before SLOs are violated. For example, Causely proactively pinpoints if a software update changes performance behaviors for dependent services before those services are impacted.
- Service impact analysis. Causely automatically analyzes the impact of the root causes on SLOs, prioritizing the root causes based on the violated SLOs and the ones that are at risk. Causely automatically defines standard SLOs (based on latency and error rate) and uses machine learning to improve its anomaly detection over time. However, environments that already have SLO definitions in another system can easily be incorporated in place of Causely’s default settings.
- Contextual presentation. The results are intuitively presented in the Causely UI, enabling users to see the root causes, related symptoms, the service impacts and initiate remedial actions. The results can also be sent to external systems to alert teams who are responsible for remediating root cause problems, to notify teams whose services are impacted, and to initiate incident response workflows.
- Prevention analysis. Teams can also ask "what if'' questions to understand the impact that potential problems might have if they were to occur to support the planning of service/architecture changes, maintenance activities and improving the resilience of services.
- Postmortem analysis. Teams can also review prior incidents and see clear explanations of why these occurred and what the effect was, simplifying the process of postmortems, enabling actions to be taken to avoid re-occurrences.
Conclusion
Troubleshooting doesn’t have to dominate a developer’s or SRE’s nightmare when the right systems are in place. Empower yourself with the only system that solves the root cause analysis problem to make troubleshooting a small, manageable part of your job.
Book a meeting with the Causely team and let us show you how to stop troubleshooting and consistently meet your reliability expectations in cloud-native environments.
