Bridging the Gap Between Observability and Automation with Causal Reasoning
Causely
May 22, 2024
Observability has become a growing ecosystem and a common buzzword. Increasing visibility with observability and monitoring tools is helpful, but stopping at visibility isn’t enough. Observability lacks causal reasoning and relies mostly on people to connect application issues with potential causes.
Causal reasoning solves a problem that observability can’t
Combining observability with causal reasoning can revolutionize automated troubleshooting and boost application health. By pinpointing the “why” behind issues, causal reasoning reduces human error and labor.
This triggers a lot of questions from application owners and developers, including:
- What is observability?
- What is the difference between causal reasoning and observability?
- How does knowing causality increase performance and efficiency?
Let’s explore these questions to see how observability pairs with causal reasoning for automated troubleshooting and more resilient application health.
What is Observability?
Observability can be described as observing the state of a system based on its outputs. The three common sources for observability data are logs, metrics, and traces.
- Logs provide detailed records of ordered events.
- Metrics offer quantitative but unordered data on performance.
- Traces show the journey of specific requests through the system.
The goal of observability is to provide insight into system behavior and performance to help identify and resolve any issues that are happening. However, traditional monitoring tools are “observing” and reporting in silos.
“Observability is not control. Not being blind doesn’t make you smarter.” – Shmuel Kliger, Causely founder in our recent podcast interview
Unfortunately, this falls short of the goal above and requires tremendous human effort to connect alerts, logs, and anecdotal application knowledge with possible root cause issues.
For example, if a website experiences a sudden spike in traffic and starts to slow down, observability tools can show logs of specific requests and provide metrics on server response times. Furthermore, engineers digging around inside these tools may be able to piece together the flow of traffic through different components of the system to identify candidate bottlenecks.
The detailed information can help engineers identify and address the root cause of the performance degradation. But we are forced to rely on human and anecdotal knowledge to augment observability. This human touch may provide guiding information and understanding that machines alone are not able to match today, but that comes at the cost of increased labor, staff burnout, and lost productivity.
Data is not knowledge
Observability tools collect and analyze large amounts of data. This has created a new wave of challenges among IT operations teams and SREs, who are now left trying to solve a costly and complex big data problem.
The tool sprawl you experience, where each observability tool offers a unique piece of the puzzle, makes this situation worse and promotes inefficiency. For example, if an organization invests in multiple observability tools that each offer different data insights, it can create a fragmented and overwhelming system that hinders rather than enhances understanding of the system’s performance holistically.
This results in wasted resources spent managing multiple tools and an increased likelihood of errors due to the complexity of integrating and analyzing data from various sources. The resulting situation ultimately undermines the original goal of improving observability.
Data is not action
Even with a comprehensive observability practice, the fundamental issue remains: how do you utilize observability data to enhance the overall system? The problem is not about having some perceived wealth of information at your fingertips. The problem is relying on people and processes to interpret, correlate, and then decide what to do based on this data.
You need to be able to analyze and make informed decisions in order to effectively troubleshoot and assure continuous application performance. Once again, we find ourselves leaving the decisions and action plans to the team members, which is a cost and a risk to the business.
Causal reasoning: cause and effect
Analysis is essential to understanding the root cause of issues and making informed decisions to improve the overall system. By diving deep into the data and identifying patterns, trends, and correlations, organizations can proactively address potential issues before they escalate into major problems.
Causal reasoning uses available data to determine the cause of events, identifying whether code, resources, or infrastructure are the root cause of an issue. This deep analysis helps proactively and preventatively address potential problems before they escalate.
For example, a software development team may have been alerted about transaction slowness in their application. Is this a database availability problem? Have there been infrastructure issues happening that could be affecting database performance?
When you make changes based on observed behavior, it’s extremely important to consider how these changes will affect other applications and systems. Changes made without the full context are risky.
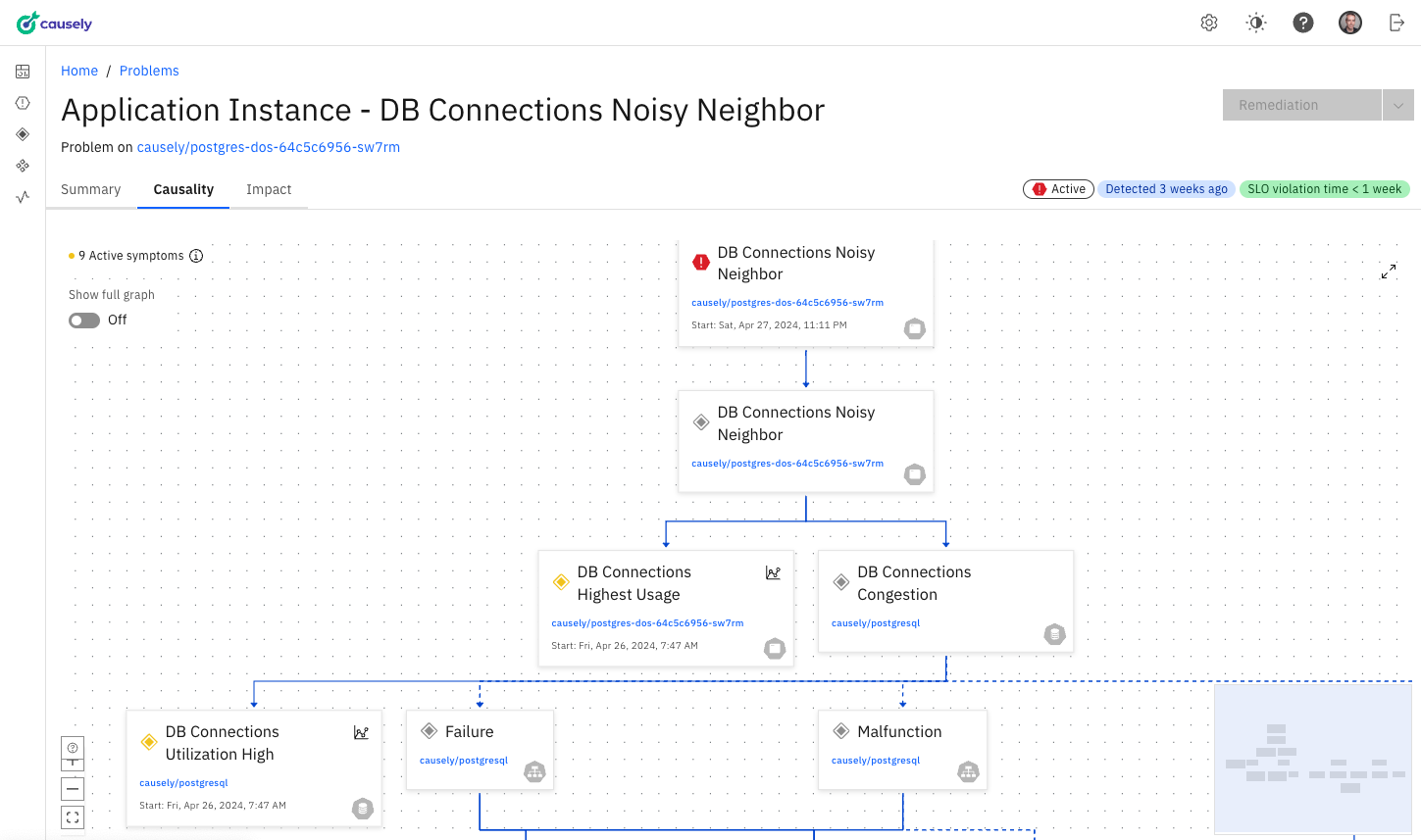
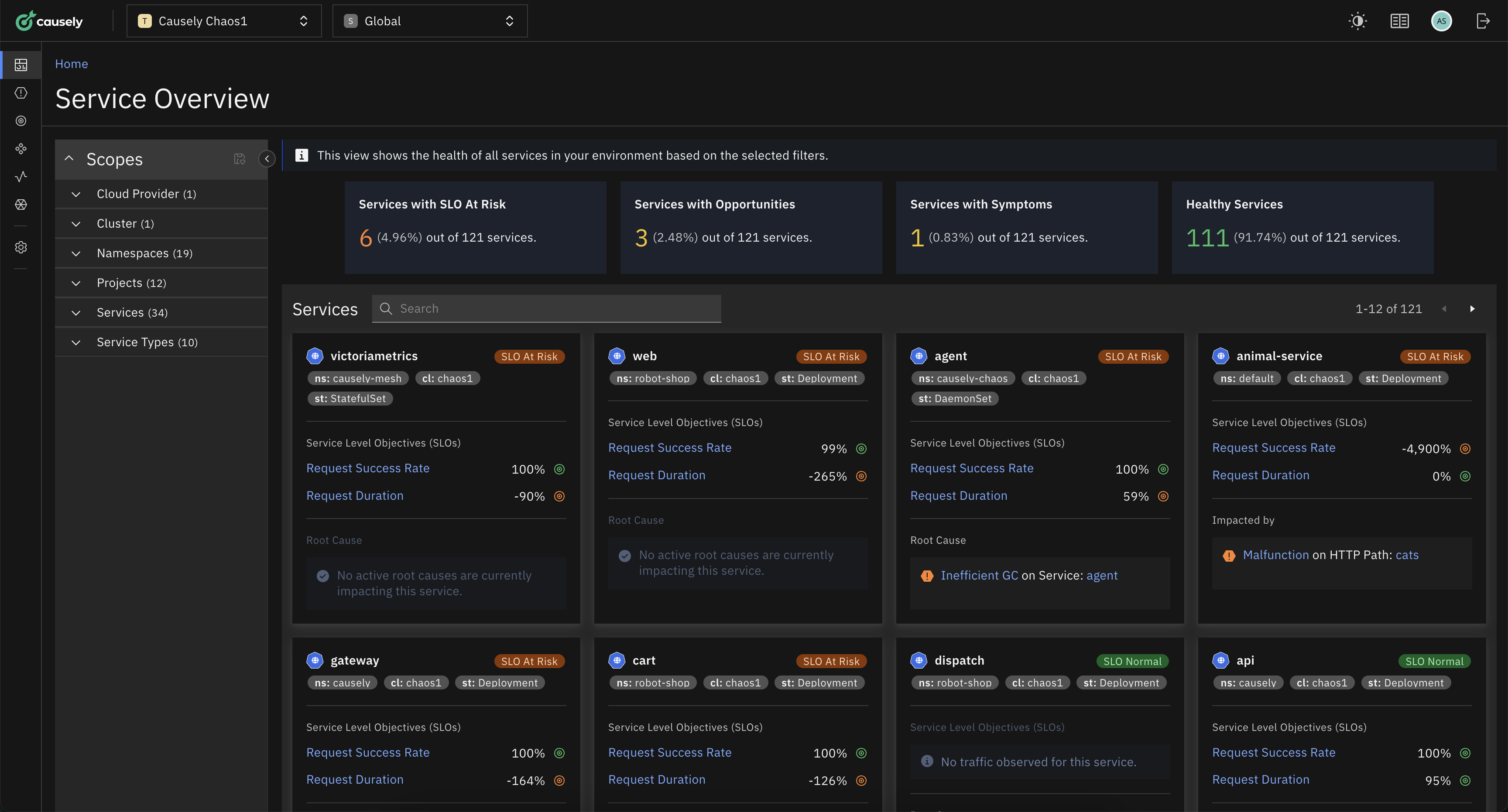
Figure 1: A PostgreSQL-based application experiencing database congestion
Using causal reasoning based on the observed environment shows that a recent update to the application code is causing crashes for users during specific transactions. A code update may have introduced inefficient database calls, which is affecting the performance of the application. That change can also go far beyond just the individual application.
If a company decides to update their software without fully understanding how it interacts with other systems, it could result in technical issues that disrupt operations and lead to costly downtime. This is especially challenging in shared infrastructure where noisy neighbors can affect every adjacent application.
Figure 2: Symptoms, causes, and impact determination
This is an illustration showing how causal AI software can connect the problem to active symptoms, while understanding the likelihood of each potential cause. This is causal reasoning in action that also understands the effect on the rest of the environment as we evaluate potential resolutions.
Now that we have causal reasoning for the true root cause, we can go even further by introducing remediation steps.
Automated remediation and system reliability
Automated remediation involves the real-time detection and resolution of issues without the need for human intervention. Automated remediation plays an indispensable role in reducing downtime, enhancing system reliability, and resolving issues before they affect users.
Yet, implementing automated remediation presents challenges, including the potential for unintended consequences like incorrect fixes that could worsen issues. Causal reasoning takes more information into account to drive the decision about root cause, impact, remediation options, and the effect of initiating those remediation options.
This is why a whole environment view combined with real-time causal analysis is required to be able to safely troubleshoot and take remedial actions without risk while also reducing the labor and effort required by operations teams.
Prioritizing action over visibility
Observability is a component of how we monitor and observe modern systems. Extending beyond observability with causal reasoning, impact determination, and automated remediation is the missing key to reducing human error and labor.
In order to move toward automation, you need trustworthy, data-driven decisions that are based on a real-time understanding of the impact of behavioral changes in your systems. Those decisions can be used to trigger automation and the orchestration of actions, ultimately leading to increased efficiency and productivity in operations.
Automated remediation can resolve issues before they escalate, and potentially before they occur at all. The path to automated remediation requires an in-depth understanding of the components of the system and how they behave as an overall system.
Integrating observability with automated remediation empowers organizations to boost their application performance and reliability. It’s important to assess your observability practices and incorporate causal reasoning to boost reliability and efficiency. The result is increased customer satisfaction, IT team satisfaction, and risk reduction.

Related resources
- What is causal AI and why do DevOps teams need it? Watch the webinar.
- Moving beyond traditional RCA in DevOps: Read the blog.
- Assure application reliability with Causely: See the product.