The “R” in MTTR: Repair or Recover? What’s the difference?
Causely
September 17, 2024
Finding meaning in a world of acronyms
There are so many ways to measure application reliability today, with hundreds of key performance indicators (KPIs) to measure availability, error rates, user experiences, and quality of service (QoS). Yet every organization I speak with struggles to effectively use these metrics. Some applications and services require custom metrics around reliability while others can be measured with just uptime vs. downtime.
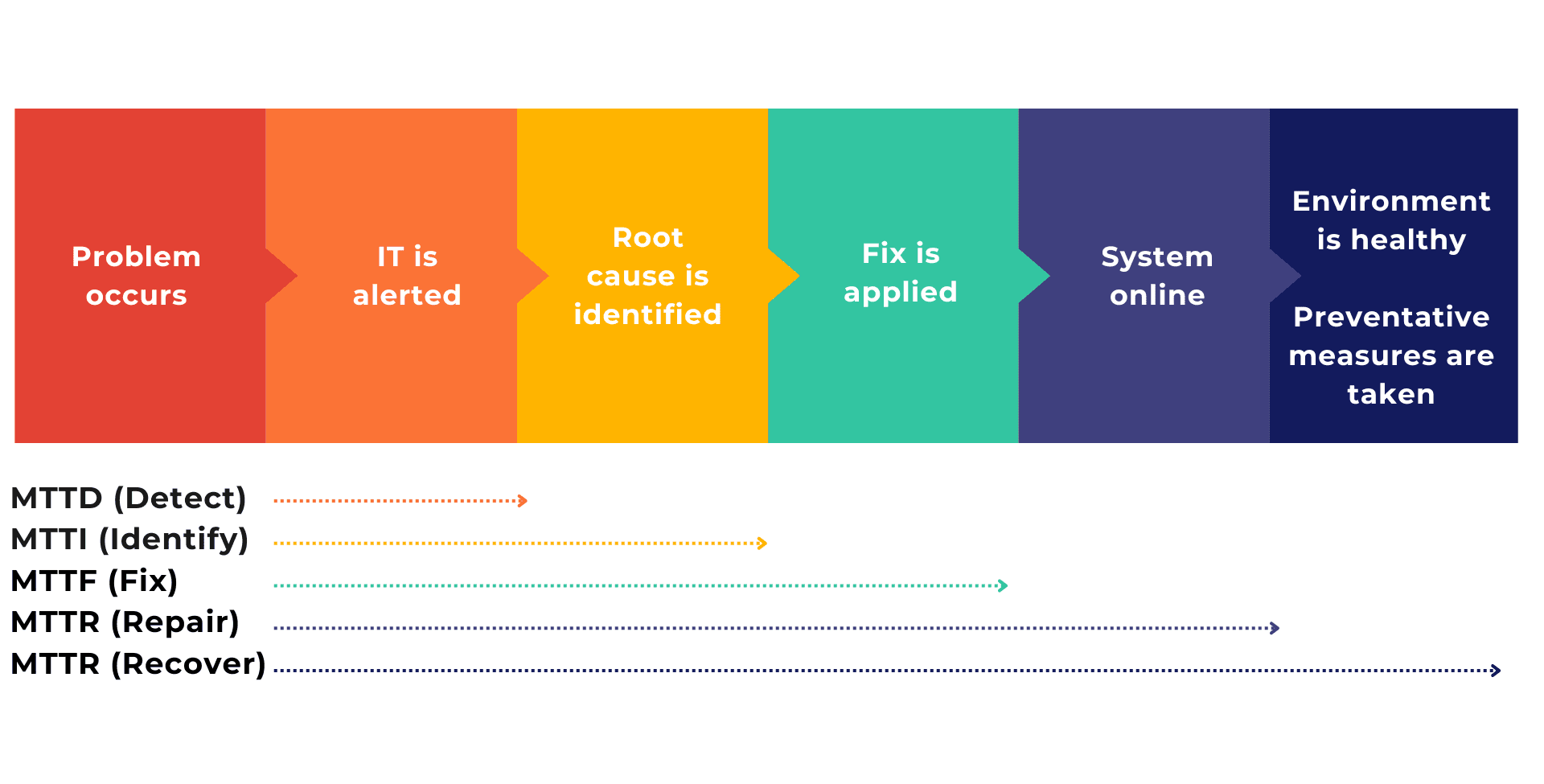
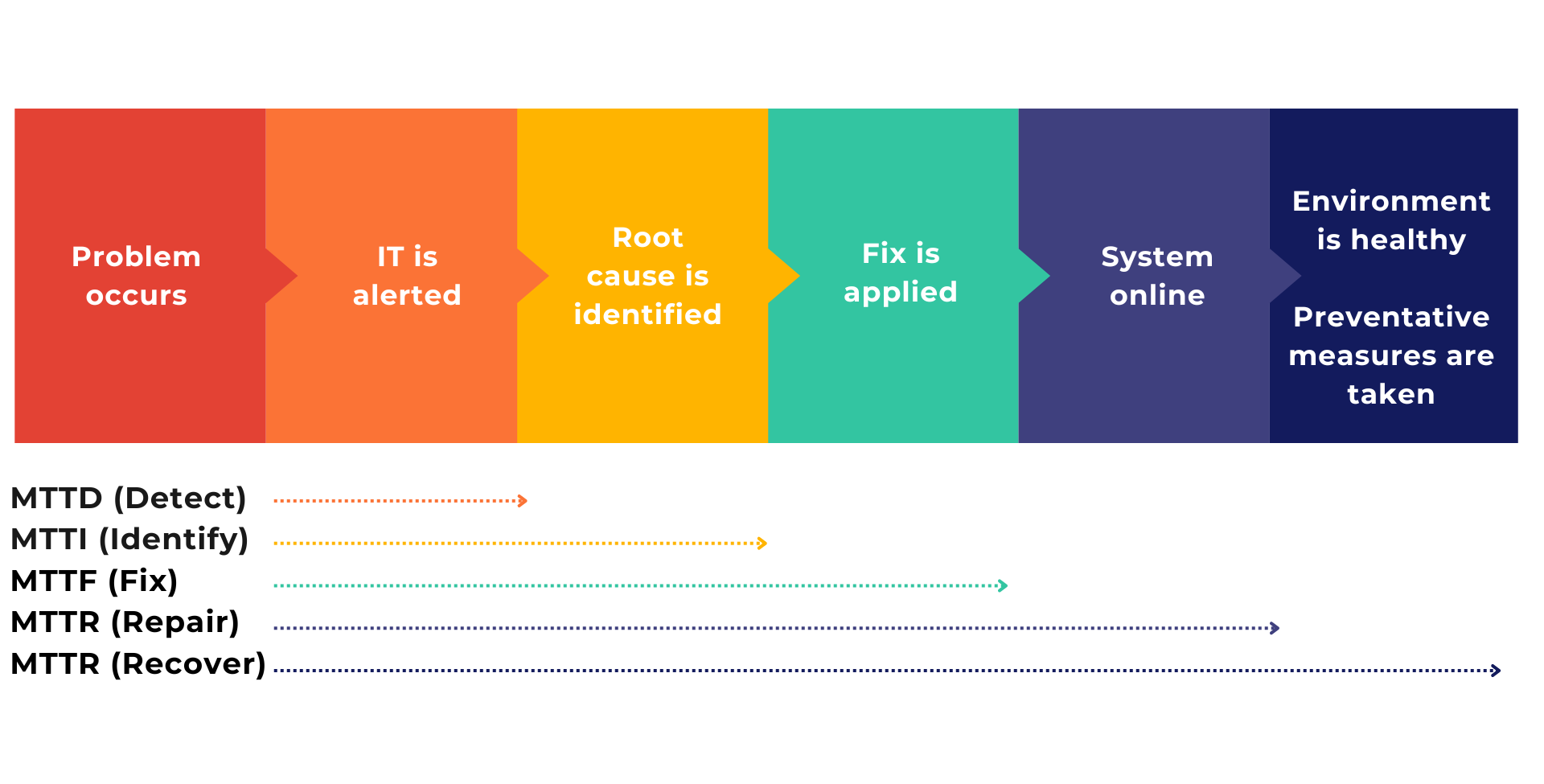
In my role at Causely, I work with companies every day who are trying to improve the reliability, resiliency, and agility of their applications. One method of measuring reliability that I keep a close eye on is MTT(XYZ). Yes, I made that up, but it’s meant to capture all the different variations of mean time to “X” out there. We have MTTR, MTTI, MTTF, MTTA, MTBF, MTTD, and the list keeps going. In fact, some of these acronyms have multiple definitions. The one whose meaning I want to discuss today is MTTR.
So, what’s the meaning of MTTR anyway?
Before cloud-native applications, MTTR meant one thing – Mean Time to Repair. It’s a metric focused on how quickly an organization can respond to and fix problems that cause downtime or performance degradation. It’s simple to calculate too:
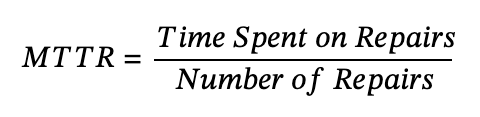
Total time spent on repairs is the length of time IT spends fixing issues, and number of repairs is the number of times a fix has been implemented. Some organizations look at this over a week or a month in production. It’s a great metric to understand how resilient your system is and how quickly the team can fix a known issue. Unfortunately, data suggests that most IT organizations’ MTTR is increasing every year, despite massive investments in the observability stack.
For monolithic applications, MTTR has historically been an excellent measurement; as soon as a fix is applied, the entire application is usually back online and performing well. Now that IT is moving toward serverless and cloud-native applications, it is a much different story. When a failure occurs in Kubernetes – where there are many different containers, services, applications, and more all communicating in real time – the entire system can take much longer to recover.
The new MTTR: Mean Time to Recover
I am seeing more and more organizations redefine the meaning of MTTR from “mean time to repair” to “mean time to recover.” Recover means that not only is everything back online, but the system is performing well and satisfying any QoS or SLAs AND a preventative approach has been implemented.
For example, take a common problem within Kubernetes: a pod enters a CrashLoopBackoff state. There are many reasons why a pod might continuously restart including deployment errors, resourcing constraints, DNS resolution errors, missing K8s dependencies, etc. But let’s say you completed your investigation and found out that your pod did not have sufficient memory and therefore was crashing/restarting. So you increased the limit on the container or the deployment and the pod(s) seems to be running fine for a bit…. but wait, it just got evicted.
The node now has increased memory usage and pods are being evicted. Or, what if now we created noisy neighbors, and that pod is “stealing” resources like memory from others on the same node? This is why organizations are moving away from repair because sometimes when the applied fix brings everything online, it doesn’t mean the system is healthy. “Repaired” can be a subjective term. Furthermore, sometimes the fix is merely a band-aid, and the problem returns hours, days, or weeks later.
Waiting for the entire application system to become healthy and applying a preventative measure will get us better insight into reliability. It is a more accurate way to measure how long it takes from a failure event to a healthy environment. After all, just because something is online does not mean it is performing well. The tricky issue here is: How do you measure “healthy”? In other words, how do we know the entire system is healthy and our preventative patch is truly preventing problems? There are some good QoS benchmarks like response time or transactions per second, but there is usually some difficulty in defining these thresholds. An improvement in MTBF (mean time between failures) is another good benchmark to test to see if your preventative approach is working.
How can we improve Mean Time to Recover?
There are many ways to improve system recovery, and ultimately the best way to improve MTTR is to improve all the MTT(XYZ) that come before it on incident management timelines.
- Automation: Automating tasks like ticket creation, assigning incidents to appropriate teams, and probably most importantly, automating the fix can all help reduce the time from problem identification to recovery. But, the more an organization scrutinizes every single change and configuration, the longer it takes to implement a fix. Becoming less strict drives faster results.
- Well-defined Performance Benchmarks: Lots of customers I speak with have a couple KPIs they track, but the more specific the better. For example, instead of making a blanket statement that every application needs to have 200ms of response time or less, set these metrics on an app by app basis.
- Chaos Engineering: This is an often-overlooked methodology to improve recovery rate. Practicing and simulating failures helps improve how quickly we can react, troubleshoot, and apply a fix. It does take a lot of time though, so it is not an easy strategy to adhere to.
- Faster Alerting Mechanisms: This is simple: The faster we get notified of a problem, the quicker we can fix it. We need to not just identify the symptoms but also quickly find the root cause. I see many companies try to set up proactive alerts, but they often get more smoke than fire.
- Knowledge Base: This was so helpful for me in a previous role. Building a KB in a system like Atlassian, SharePoint, or JIRA can help immensely in the troubleshooting process. The KB needs to be searchable and always changing as the environment evolves. Being able to search for a specific string in an error message within a KB can immediately highlight not just a root cause but also a fix.
To summarize, MTTR is a metric that needs to capture the state of a system from the moment of failure until the entire system is healthy again. This is a much more accurate representation of how fast we recover from a problem, and how resilient the application architecture is. MTTR is a principle that extends beyond the world of IT; its applications exist in security, mechanics, even healthcare. Just remember, a good surgeon is not only measured by how fast he can repair a broken bone, but by how fast the patient can recover.
Improving application resilience and reliability is something we spend a lot of time thinking about at Causely. We’d love to hear how you’re handling this today, and what metric you’ve found most useful toward this goal. Comment here or contact us with your thoughts!
