The Rising Cost of Digital Incidents: Understanding and Mitigating Outage Impact
Causely
August 8, 2024

Digital disruptions have reached alarming levels. Incident response in modern application environments is frequent, time-consuming and labor intensive. Our team has first-hand experience dealing with the far-reaching impacts of these disruptions and outages, having spent decades in IT Ops.
PagerDuty recently published a study1 that shines a light on how broken our existing incident response systems and practices are. The recent Crowdstrike debacle is further evidence of this. Even with all the investment in observability, AI Ops, automation, and playbooks, things aren’t improving. In some ways, they’re actually worse; we’re collecting more and more data and we’re overloaded with tooling, creating confusion between users and teams who struggle to understand the holistic environment and all of its interdependencies.
With a mean resolution time of 175 minutes, each customer-impacting digital incident costs both time and money. The industry needs to reset and revisit current processes so we can evolve and change the trajectory.
The impact of outages and application downtime
Outages erode customer trust. 90% of IT leaders report that disruptions have reduced customer confidence. Protecting sensitive data, ensuring swift service restoration, and providing real-time customer updates are essential for maintaining trust when digital incidents happen. Thorough, action-oriented postmortems are critical post-incident to prevent recurrences. And – at risk of reinforcing the obvious – IT organizations need to put operational practices in place to minimize outages from happening in the first place.
Yet even though IT leaders understand the implications on customer confidence, incident frequency continues to rise. 59% of IT leaders report an increase in customer-impacting incidents, and it’s not going to get better unless we change the way we observe and mitigate problems in our applications.
Automation can help, but adoption is slow
Despite the growing threat, many organizations are lagging behind in incident response automation:
- Over 70% of IT leaders report that key incident response tasks are not yet fully automated.
- 38% of responders’ time is spent dealing with manual incident response processes.
- Organizations with manual processes take on average 3 hours 58 minutes to resolve customer-impacting incidents, compared to 2 hours 40 minutes for those with automated processes.
It doesn’t take an IT expert to know that spending nearly half their time in manual processes is a waste of resources. And those that have automated operations are still taking almost 3 hours to resolve incidents. Why is incident response still so slow?
It’s not just about process automation. We also need to accelerate decision automation, driven by a deep understanding of the state of applications and infrastructure.
Causal reasoning: The missing link
Causal reasoning technology promises a bridge between observability and automated incident response. We're referring to causal reasoning software that applies machine learning to automatically capture cause and effect relationships. This has the potential to help Dev and Ops teams better plan for changes to code, configurations or load patterns, so they can stay focused on achieving service-level and business objectives instead of firefighting.
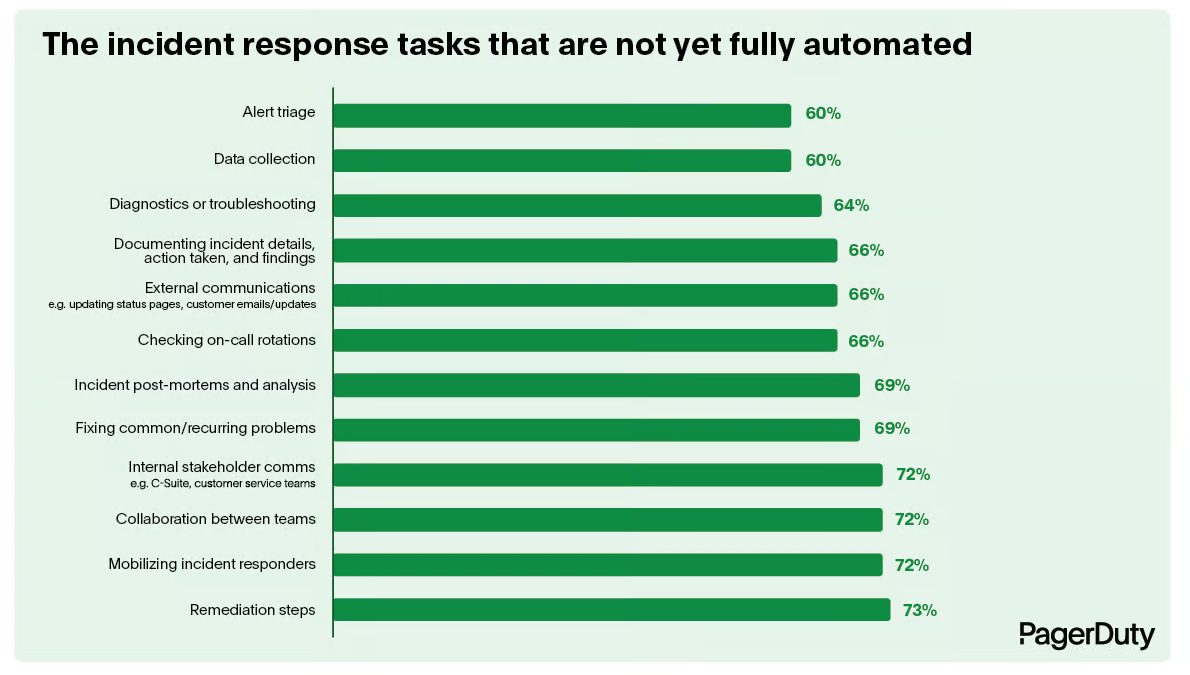
With causal reasoning technology, many of the incident response tasks that are currently manual can be automated:
- When service entities are degraded or failing and affecting other entities that make up business services, causal reasoning software surfaces the relationship between the problem and the symptoms it’s causing.
- The team with responsibility for the failing or degraded service is immediately notified so they can get to work resolving the problem. Some problems can be remediated automatically.
- Notifications can be sent to end users and other stakeholders, letting them know that their services are affected along with an explanation for why this occurred and when things will be back to normal.
- Postmortem documentation is automatically generated.
- There’s no more complex triage processes that would otherwise involve multiple teams and managers to orchestrate. Incidents and outages are reduced and root cause analysis is automated, so DevOps teams spend less time troubleshooting and more time shipping code.
Introducing Causely
This potential to transform the way DevOps teams work is why we built Causely. Our Causal Reasoning Platform automatically pinpoints the root cause of observed symptoms based on real-time, dynamic data across the entire application environment. Causely transforms incident response and improves mean time to resolution (MTTR), so DevOps teams focus on building new services and innovations that propel the business forward.
By automatically understanding cause-and-effect relationships in application environments, Causely also enables predictive maintenance and better overall operational resilience. It can help to prevent outages and identify the root cause of potential issues before they escalate.
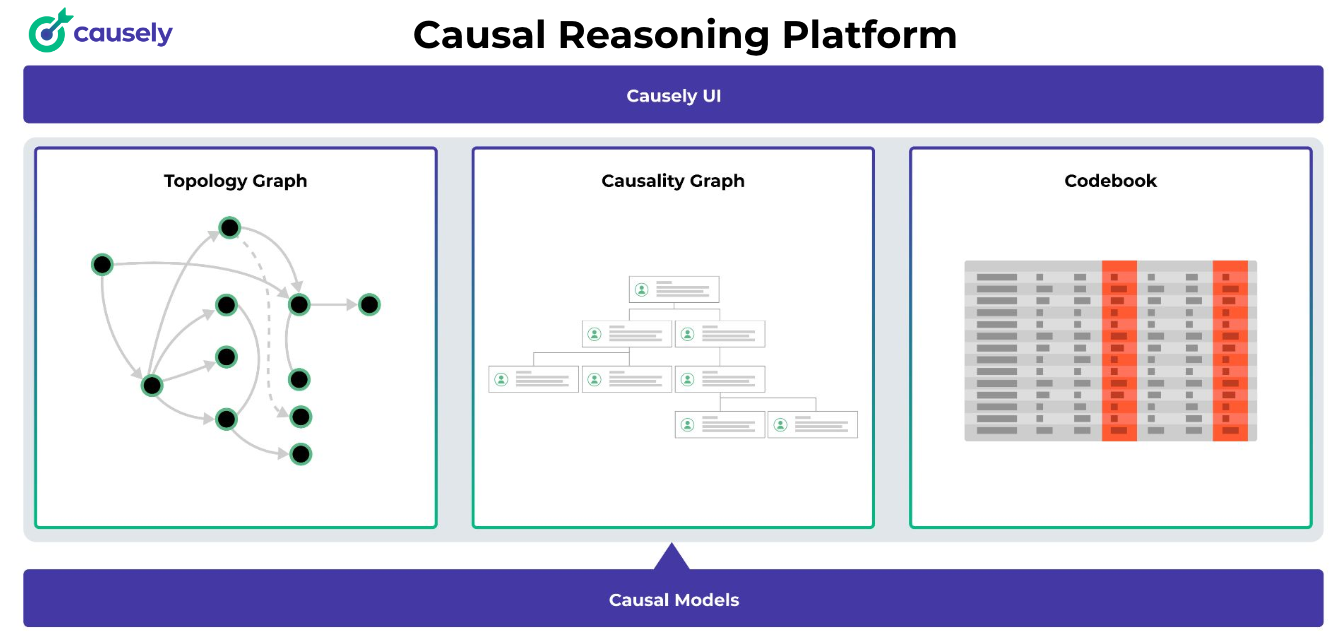
Here’s how it works, at a high level:
- Our Causal Reasoning Platform is shipped with out-of-the-box Causal Models that drive the platform’s behavior.
- Once deployed, Causely automatically discovers the application environment and generates a Topology Graph of it.
- A Causality Graph is generated by instantiating the Causal Models with the Topology Graph to reflect cause and effect relationships between the root causes and their symptoms, specific to that environment at that point in time.
- A Codebook is generated from the Causality Graph.
- Using the Codebook, our Causal Reasoning Platform automatically and continuously pinpoints the root cause of issues.
Users can dig into incidents, understand their root causes, take remediation steps, and proactively plan for new releases and application changes – all within Causely.
This decreases downtime, enhances operational efficiency, and improves customer trust long-term.
It’s time for a new approach
It’s time to shift from manual to automated incident response. Causely can help teams prevent outages, reduce risk, cut costs, and build sustainable customer trust.
Don’t hesitate to contact us about how to bring automation into your organization, or you can see Causely for yourself.
1 “Customer impacting incidents increased by 43% during the past year- each incident costs nearly $800,000.” PagerDuty. (2024, June 26). https://www.pagerduty.com/resources/learn/cost-of-downtime/
Related resources
- Read the blog: DevOps may have cheated death, but do we all need to work for the king of the underworld?
- Learn about our Causal Reasoning Platform
- See Causely for yourself