Understanding failure scenarios when architecting cloud-native applications
Causely
December 8, 2023
Developing and architecting complex, large cloud-native applications is hard. In this short demo, we’ll show how Causely helps to understand failure scenarios before something actually fails in the environment.
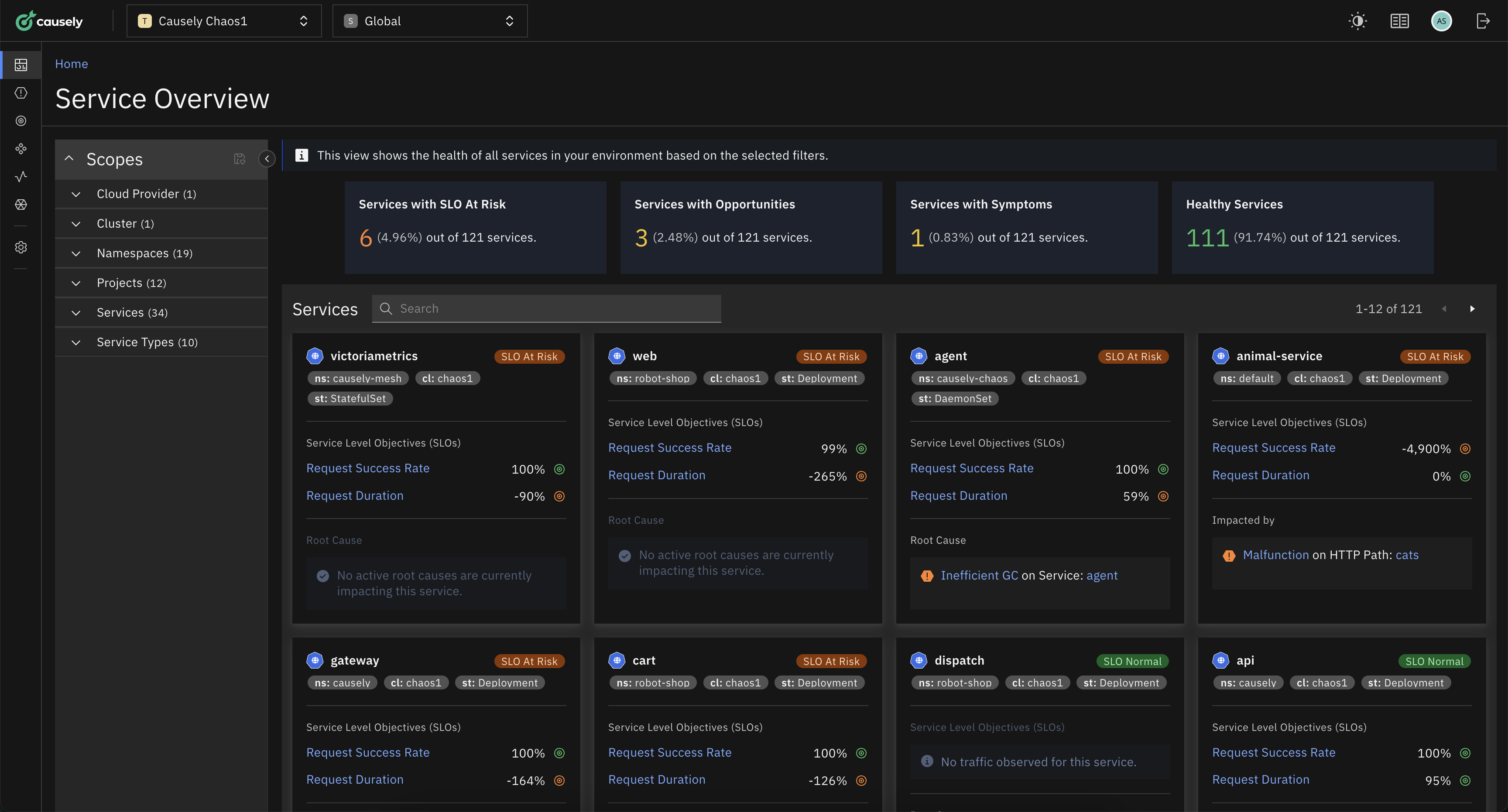
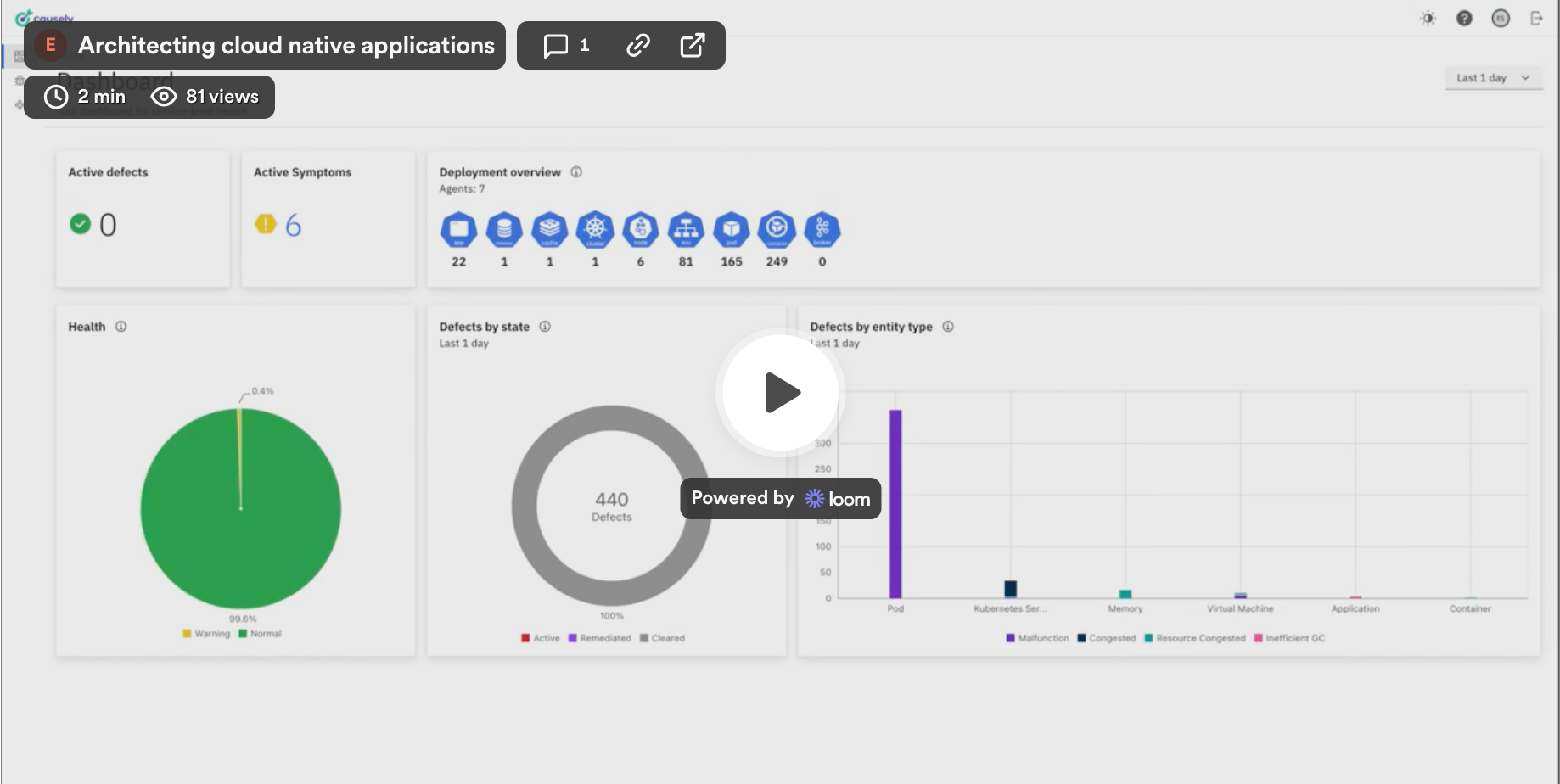
In the demo environment we have a dozen applications with database servers, caches running in a cluster, providing multiple services. If we drill into these services and focus on the application, we can only see how the application is behaving right now. But Causely is automatically identifying the potential root causes and alerts that would be caused – services that would be impacted – by failures.
For example, a congested service would cause high latency across a number of different downstream dependencies. A malfunction of this service would make services unavailable and cause high error rates on the dependent services.
Causely is able to reason about the specific dependencies and all the possible root causes – not just for services, but for the applications – in terms of: what would happen if their database query takes too long, if their garbage collection time takes too long, if their transaction latency is high? What services would be impacted, and what alerts would it receive?
This allows developers to design a more resilient system, and operators can understand how to run the environment with their actual dependencies.
We’re hoping that Causely can help application owners avoid production failures and service impact by architecting applications to be resilient in the first place.
What do you think? Share your comments on this use case below.